WEKA Makes GPUs 20x Faster

GPUs are Fast.
WEKA Makes Them Faster.
20x Faster.
GPUs have become the gold standard for intensive workloads because they are fast. But what happens when your GPUs spend half their day sitting idle? To be truly fast and efficiently train AI models, GPUs must be fed data continuously.
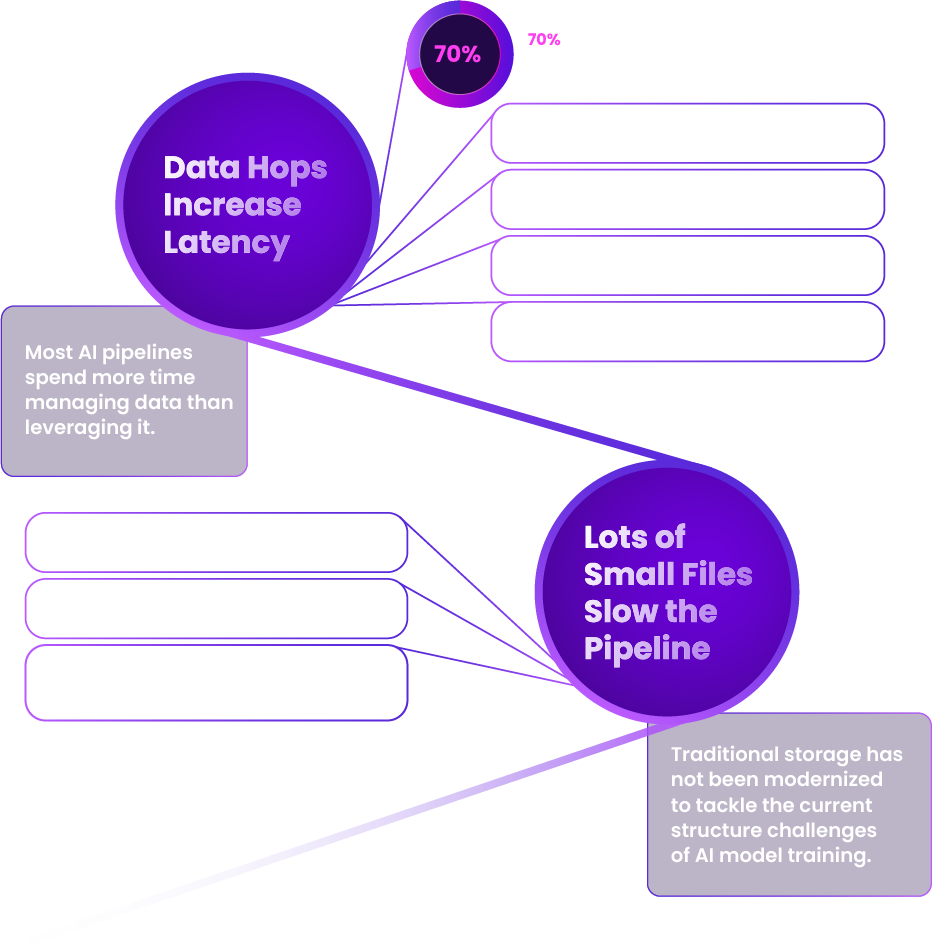
Data-hungry GPUs sitting idle at the end of a congested data pipeline cost time, money, and insights.
Does your data spend more time standing in line than it does training your model/feeding your GPUs?
GPUs Are Starved for Data
Why? The current AI pipeline was not designed to optimize AI workloads.
Get the Most Out of Your GPUs
With the WEKA Data Platform, get your data moving through the pipeline, feed your GPUs continuously, and solve more problems, faster.
How does WEKA make the GPU 20X faster? 

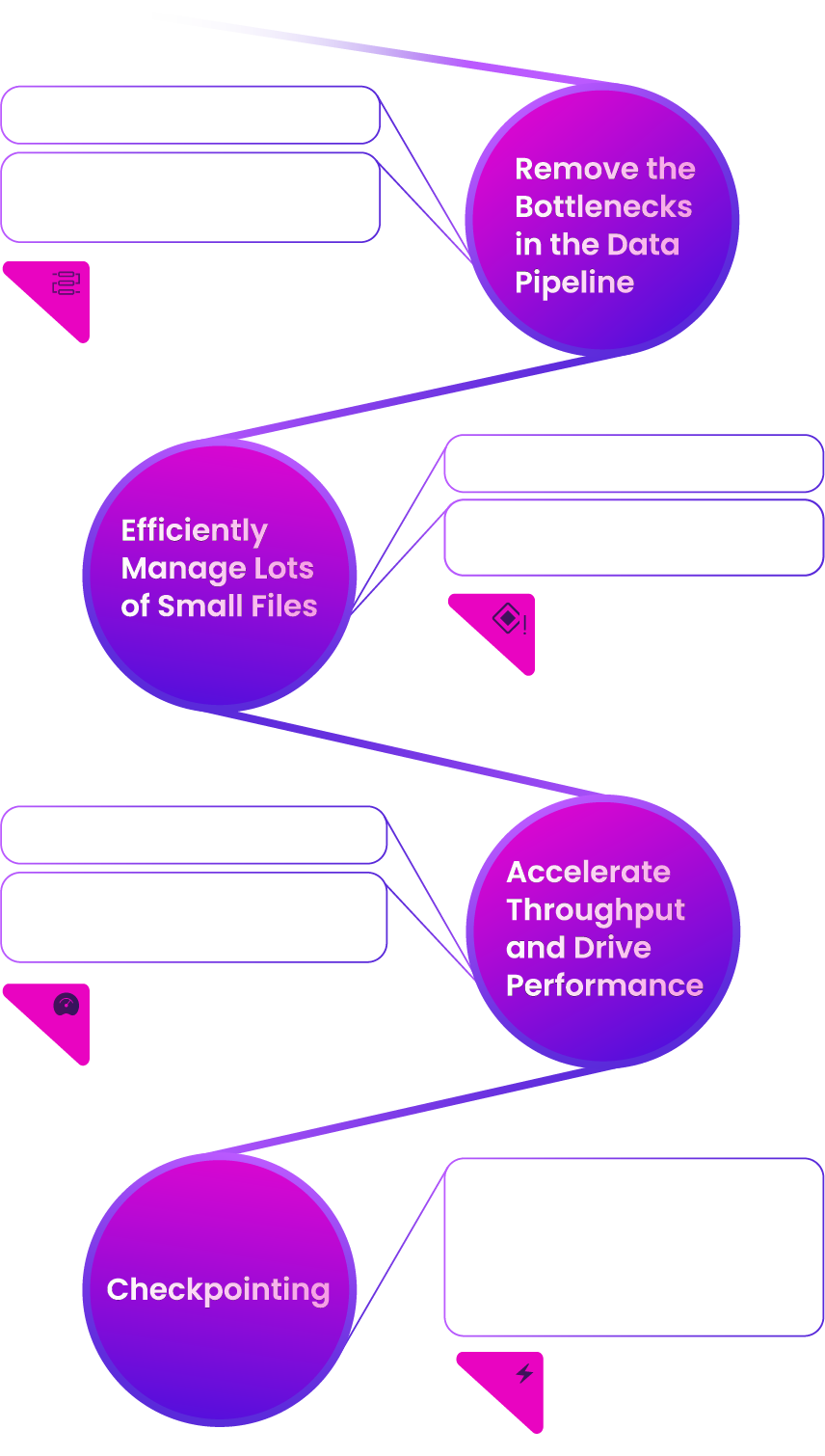
With a modern data pipeline engineered for intensive AI workloads, you can get your data moving, optimize your GPUs, and train your model faster.
And all of that means you get quicker answers to more of the problems that matter most to your business.
© 2024 WekaIO, Inc. All rights reserved. WKA380-01 03/24