Distributed File Systems (DFS)
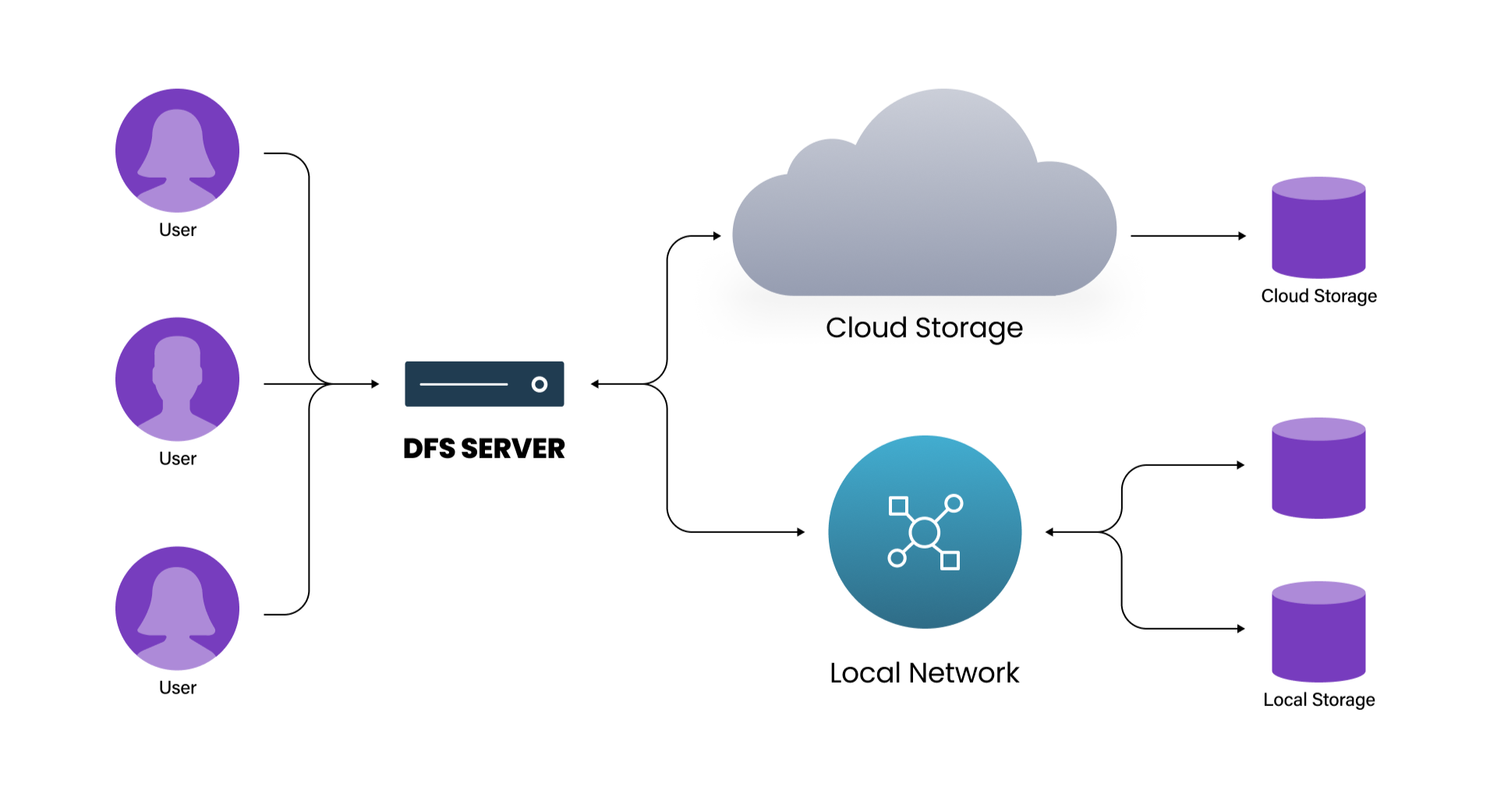
What is a Distributed File System?
A distributed file system (DFS) differs from typical file systems (i.e., NTFS and HFS) in that it allows direct host access to the same file data from multiple locations. Indeed, the data behind a DFS can reside in a different location from all of the hosts that access it.
How Does Distributed File System Work?
A distributed file system (DFS) is a file system that spans multiple machines or nodes in a network. It allows multiple users to access files and share resources transparently, as if they were stored on a single machine.
DFS Namespaces
DFS namespaces play a crucial role in how a distributed file system works, providing a logical structure and domain based namespaces with conventions for files and directories. A DNS namespace acts as an abstraction layer that allows clients to access files and directories using familiar paths, regardless of their physical location within the distributed file system.
Here are some key aspects and functions of DFS namespaces:
Hierarchical structure. DFS namespaces typically follow a tree-like hierarchical structure similar to traditional file systems. The structure is simple and intuitive, directories can contain both files and subdirectories, and file organization and management is easy.
Naming conventions. Namespaces define naming conventions for files and directories. Clients can refer to files using paths, such as “/path/to/file.txt,” where “/” represents the root of the namespace. Namespaces may enforce rules for valid characters, length limitations, and case sensitivity in file and directory names.
Location transparency. The primary benefit of namespaces is location transparency. Clients can access files and directories using their logical names without needing to know their physical locations or the underlying distribution of where file data is stored physically across the cluster.
Metadata management. Namespaces are closely tied to a distributed file system’s metadata management component, maintaining information about the structure and attributes of files and directories within the namespace. The namespace tracks file names, directory hierarchy, ownership, permissions, timestamps, and the mapping of logical names to physical block locations.
Namespace operations. Clients can perform various operations on the namespace, such as creating directories, deleting files, moving or renaming files, and listing the contents of directories. These operations are typically exposed through a file system interface or an API provided by the distributed file system.
Scalability and load balancing. Namespaces allow the DFS to distribute files and directories across multiple servers, enabling parallel access and reducing the load on individual nodes. This achieves better performance and helps accommodate large-scale storage requirements.
In the context of Distributed File Systems (DFS) and their architecture, a DFS root refers to the starting point or the top-level entry point of a DFS namespace. It serves as the logical container or parent folder that encompasses the entire namespace structure.
A domain controller DFS refers to the integration of a DFS with the active directory domain services (AD DS) infrastructure within a Windows Server environment. In this context, the domain controller (DC) acts as the server responsible for managing and providing access to DFS namespaces and shares within an active directory domain.
Briefly, a domain controller DFS works like this:
The active directory domain services (AD DS). The AD DS provided by Microsoft Windows Server stores information about users, groups, computers, and other objects within a network and enables centralized management and authentication for network resources.
DFS namespace on domain controller. DFS Namespace is a logical view of shared folders across multiple servers and locations. It provides a unified namespace that allows users to access files and folders using a consistent path. This way, the DFS domain namespace is integrated into the Active Directory domain.
Integration with active directory. When DFS is integrated with AD DS, the DFS namespace information is stored within the active directory database, ensuring availability and consistency across the network.
High availability. With DFS on domain controllers in place, DFS namespace information is replicated to multiple domain controllers, ensuring high availability and fault tolerance. Should one controller become unavailable, seamless failover to an available domain controller takes over.
A DFS standalone namespace and a domain-based namespace are two different approaches to organizing and managing namespaces within a Distributed File System (DFS) infrastructure.
A standalone DFS namespace refers to a DFS namespace that operates independently without being integrated with a larger DFS infrastructure. A standalone DFS namespace does not collaborate or integrate with other DFS servers, but operates independently to provide the namespace functionality, manage the namespace hierarchy, metadata, and access to files and directories. A domain-based namespace leverages the domain infrastructure, specifically domain controllers, for namespace management. Each domain controller manages a portion of the namespace within its respective domain.
Here are some key aspects and characteristics of a DFS root:
Namespace container. A DFS root acts as a container or directory that holds the entire DFS namespace structure at the highest level of the namespace hierarchy.
Logical entry point. The DFS root provides a logical entry point for clients to access the DFS namespace. Clients can connect to the DFS root using its network path, which typically starts with the server name or domain name and is followed by the DFS root name.
Multiple roots. A DFS environment can have multiple DFS roots, each with its own configuration and hierarchy. This allows administrators to organize and manage different sets of shared folders under different DFS roots.
Access and permissions. Like any other folder or directory, the DFS root can have its own access control permissions. Administrators can assign permissions to control who can access and manage the DFS root and the shared folders within the namespace.
Distributed File System Architecture
A distributed file system consists of a cluster of machines/nodes interconnected by a network. These machines collaborate to provide a unified file system interface to clients.
Distributed file system architecture refers to the underlying design and arrangement of components that together form a distributed file system. DFS architecture plays a critical role in shaping the characteristics and behavior of the distributed file system, including its scalability, fault tolerance, performance, and overall functionality.
While specific DFS architectures may vary, here are some common elements:
Client-server architecture model. Typically, DFS architecture follows a client-server model. Clients are the entities that access and utilize the distributed file system, while servers or nodes are responsible for storing and serving the files. Clients interact with servers to perform file operations such as reading, writing, and metadata management.
Metadata server. Many DFS architectures have a dedicated metadata server or set of servers responsible for managing the metadata of the distributed file system. The metadata server maintains information about the file system structure, file attributes, access control, and the mapping between logical file names and physical file locations. The metadata server provides a centralized authority for file system management and coordination.
Data storage nodes. Data storage nodes are servers that store actual file data and hold blocks or chunks of the file to respond to read and write requests from clients. Data storage nodes maintain multiple copies of the data across different servers, employing data replication techniques to enhance fault tolerance and data availability.
Network communication. Distributed file systems may leverage network protocols such as TCP/IP, UDP, or specialized protocols optimized for distributed storage environments.
Caching strategies. Distributed file systems often incorporate caching mechanisms such as storing frequently accessed data closer to the clients or in intermediary nodes to improve performance. Caching strategies aim to minimize network overhead by reducing the need for repeated data transfers. Caches can exist at the client-side, server-side, or within intermediary layers of the distributed file system.
Fault tolerance and replication. Distributed file systems emphasize fault tolerance to ensure data availability in case of failure. Replication implemented in full or in part, via erasure coding, or using RAID-like techniques can store multiple copies of data across different nodes.
Consistency and coherency. Ensuring that multiple clients see a consistent view of the file system and that concurrent operations on shared files are properly coordinated is challenging. Distributed file systems employ techniques such as distributed locks, distributed transactions, or consistency protocols to manage concurrent access and maintain data consistency.
File Service Architecture in Distributed System
File service architecture in a distributed system refers to a design approach that provides a distributed file system for managing and accessing files across multiple machines or nodes. It enables users and applications to interact with files as if they were stored on a single, centralized system, even though the files are physically distributed across different machines in a network.
The key components of a file service architecture typically include:
File server. A central server or a set of servers that manage the storage and retrieval of files and handles file system operations such as file creation, deletion, and modification.
File clients. Machines or nodes that request file services from the file server. File clients can be both user machines and application servers that need access to the files stored in the distributed system.
File metadata. Metadata contains information about files, such as file names, file sizes, permissions, timestamps, and directory structures. The file server maintains the metadata to facilitate file operations and track file attributes.
File access protocol. A protocol or set of protocols (for example Network File System [NFS] and Common Internet File System [CIFS/SMB]) that define how file clients communicate with the file server to perform file operations.
File replication and consistency. In distributed file systems, files are often replicated across multiple servers or nodes for improved availability and fault tolerance. Replication mechanisms ensure that changes are made while data consistency is maintained.
Caching. DFS systems improve performance with caching mechanisms that store frequently accessed files or parts of files closer to requesting clients. Caching reduces the need for network transfers and speeds up file access.
Remote File Access in Distributed System
Various distributed file system types allow remote access across systems. Here are some common file accessing models in distributed systems:
Network file system (NFS). NFS, a widely used file access protocol, allows remote file access in a distributed system. It enables a client machine to access a remote file system as if it were local, and then perform standard file operations, such as reading, writing, and modifying files, as if they were stored locally.
Common internet file system (CIFS/SMB). CIFS (also called SMB) is a network file sharing protocol used mostly in Windows environments. CIFS/SMB allows clients to access and share remote files and directories across a network as if they were local and supports file locking, authentication, and printer sharing.
Hadoop distributed file system (HDFS). HDFS is a distributed file system designed for storing and processing large datasets in a distributed computing environment, commonly used in big data applications. HDFS divides files into blocks and distributes them across multiple machines in a cluster, offering fault tolerance and high throughput for parallel data processing.
GlusterFS. GlusterFS is an open-source distributed file system that aggregates disk storage resources from multiple servers into a unified global namespace. It allows clients to access files stored in the system as if they were local files. GlusterFS uses a scalable architecture with a centralized metadata server and distributed storage servers for remote file access.
Lustre. Lustre is a high-performance parallel distributed file system designed for large-scale computing and storage clusters often used in scientific computing and supercomputing environments.
Caching in Distributed File System
Caching. Distributed file systems improve their performance using client-side caching of data that is frequently accessed, reducing the need for network round-trips.
File partitioning. The file system divides files into smaller units, often called blocks or chunks. Each block has a unique identifier and can be stored on any machine in the cluster. How blocks are distributed across machines is typically managed by a distributed file system controller or metadata server.
Data replication and redundancy. Distributed file systems often replicate data across multiple machines to enhance reliability and availability, ensuring that if one machine fails, the data remains accessible. Replication also improves read performance, allowing clients to retrieve data from nearby replicas.
Client interaction. Clients interact with the distributed file system using a library or protocol. When a client wants to read or write a file, they contact the metadata server to obtain the location of the required blocks and then directly communicate with the appropriate machines to perform read or write operations.
Consistency and coherency. Distributed file systems employ techniques such as distributed locks, distributed transactions, or consistency protocols to ensure that multiple clients accessing the same file see consistent data.
Distributed File System Design
There are several key steps in the distributed file system design process:
Identify requirements. Identify the specific requirements of the distributed file system and the types of applications and workloads that will interact with it. Consider performance, scalability, fault tolerance, data consistency, security, ease of use, and other relevant factors.
Determine architecture. Based on the requirements, determine the appropriate architecture. Consider factors such as centralized vs. decentralized, client-server vs. peer-to-peer, and the need for replication and caching. Choose an architecture that aligns with and supports desired performance, scalability, and fault tolerance goals.
Define data model. Determine how files and directories will be organized and represented, and define the metadata structure, including file attributes, permissions, timestamps, directory structure, and techniques for efficient file lookup and metadata management.
Replication strategy. Define the replication strategy where replication is required for fault tolerance or performance reasons. Clarify the number of replicas, replication consistency models, and mechanisms for handling replication conflicts and data consistency across replicas.
File access protocol. Select a file access protocol that allows clients to interact with the distributed file system. Consider established protocols like POSIX, NFS, CIFS/SMB, or choose to design a custom protocol tailored to the specific requirements of the system.
Security design. Determine which security mechanisms to implement. Define authentication mechanisms, access control policies, encryption requirements, and auditing and monitoring capabilities. Ensure the security design aligns with organizational security policies and standards.
Performance optimization. Identify potential performance bottlenecks and consider caching, load balancing, data partitioning, parallel processing, and other techniques to enhance system performance.
Fault tolerance and recovery. Design failure recovery mechanisms to ensure availability. Define fault tolerance mechanisms such as data replication, distributed consensus protocols, and error recovery procedures. Establish backup and recovery strategies to protect against data loss and facilitate system restoration.
Scalability and growth. Account for growth and scalability requirements and consider horizontal scaling, dynamic resource allocation, and load balancing to accommodate future needs. Design the distributed file system to handle increasing data volumes, user loads, and the addition of new nodes or servers.
Implementation and testing. Implement the designed DFS, and conduct thorough testing, including unit testing, integration testing, performance testing, and security testing.
Deployment and monitoring. Deploy the distributed file system in the target environment. Continuously monitor the system’s performance, availability, and security, and optimize and fine-tune the system based on real-world usage patterns and feedback.
Distributed File System Features
- Transparent local access – From a host perspective, the data is accessed as if it’s local to the host that is accessing it.
- Location independence – Multiple host servers may have no idea where file data is stored physically. Data location is managed by the DFS and not by the host accessing it.
- Coherent access – DFS shared file data is managed so that it appears to the host(s) as if it’s all within a single file system, even though its data could be distributed across many storage devices/servers and locations.
- Great large-file streaming throughput – DFS systems emerged to supply high-streaming performance for HPC workloads, and most continue to do so.
- File locking – DFSs usually support file locking across or within locations, which ensures that no two hosts can modify the same file at the same time.
- Data-in-flight encryption – Most DFS systems support encrypting data and metadata while it is in transit.
- Diverse storage media/systems – Most DFS systems can make use of spinning disk, SAS SSDs, NVMe SSDs, and S3 object storage, as well as private, on-premises object storage to hold file data. While most DFS systems have very specific requirements for metadata servers, their data or file storage can often reside on just about any storage available, including the public cloud.
- Multi-protocol access – Hosts can access data using standard NFS, SMB, or a POSIX client supplied by the solution provider. Occasionally one can also see NVMe-oF for files and (NVIDIA) GPU Direct Storage access. This can also mean that copies of the file can be accessed with all protocols the DFS solution supports.
- Multi-networking access – While all DFSs provide Ethernet access to file system data, some also provide InfiniBand and other high performance networking access.
- Local gateways – DFS systems may require some server and storage resources at each location that can access files and their data. Local gateways often cache metadata and data referenced by hosts. Gateways like this can typically be scaled up or down to sustain performance requirements. In some cases where access and data reside together, gateways are not needed.
- Software-defined solutions – Given all the above, most DFS systems are software defined solutions. Some DFS systems are also available in appliance solutions, but that is more for purchasing/deployment convenience than a requirement of the DFS solution.
- Scale-out storage solution – Most DFS systems support scale-out file systems in which file data and metadata service performance and capacity can be increased by adding more metadata or file data server resources–which includes gateways.
Characteristics of a Modern Distributed File System
- High IOPS/great small-file performance – Some DFS systems support very high IOPS for improved small file performance.
- Cross-protocol locking – Some DFS systems allow for one protocol to lock a file while being modified by another protocol. This feature prohibits a file from being corrupted by multi-host access even when accessing the file with different protocols.
- Cloud resident services – Some DFS solutions can run in a public cloud environment. That is, their file data storage, metadata services, and any monitoring/management services all run in a public cloud provider. File data access can then take place all within the same cloud AZ or across cloud regions or even on premises with access to that cloud data.
- High availability support – Some DFS systems also support very high availability by splitting and replicating their control, metadata, and file data storage systems across multiple sites, AZs or servers.
- (File) data reduction – Some DFS solutions support data compression or deduplication designed to reduce the physical data storage space required to store file data.
- Data-at-rest encryption – Some DFS systems offer encryption of file data and metadata at rest.
Single name space – Some DFS systems provide the ability to stitch multiple file systems/shares into a single name space, which can be used to access any file directory being served.
Distributed File System Security
Securing a distributed file system is crucial to protect sensitive data, maintain data integrity, and prevent unauthorized access. Here are some best practices for distributed file system security:
Authentication and access control. Implement strong authentication such as public key cryptography and multi-factor authentication. Use access control lists (ACLs) or role-based access control (RBAC) to enforce granular permissions and restrict access to files and directories based on user roles or groups.
Encryption. Encrypt data in transit and at rest to protect it from unauthorized interception or access. Use secure protocols such as TLS (Transport Layer Security) or SSH (Secure Shell) for secure communication between clients and servers. Implement encryption mechanisms for data stored in the distributed file system, such as disk-level encryption or file-level encryption, to ensure that even if the data is compromised, it remains unreadable without the encryption keys.
Auditing and monitoring. Enable auditing and logging mechanisms to track file system activities and monitor for suspicious or unauthorized actions. Log file accesses, modifications, and permission changes for accountability and forensic analysis. Implement real-time monitoring and intrusion detection systems to detect and respond to security incidents promptly.
Network segmentation and firewalls. Segment the network to isolate it from other critical systems. Use firewalls and network access control lists (ACLs) to restrict network traffic and allow only authorized communication between clients and servers. Employ network intrusion detection and prevention systems (IDS/IPS) to detect and block malicious network traffic.
Regular updates and patch management. Keep distributed file system software and underlying operating systems up to date with the latest security patches and updates. Monitor for security advisories and apply patches promptly to address any identified vulnerabilities.
Backup and disaster recovery. Conduct regular backup procedures and store backups securely, preferably off-site, in encrypted form. Establish a disaster recovery plan, including procedures for restoring data and resuming operations in case of any type of incident.
Employee education and awareness. Educate users and administrators about best practices and potential risks. Teach users to recognize and avoid phishing attacks, and provide training on secure file handling and sharing practices.
Regular security audits. Conduct periodic security audits and penetration testing to identify vulnerabilities and assess security controls. Engage third-party security professionals to perform independent audits and vulnerability assessments to ensure a thorough evaluation.
Distributed File System Implementation
Specific implementation details vary:
File system architecture. Architecture for the distributed file system design and implementation includes differences such as centralized vs. decentralized, client-server vs. peer-to-peer, and the use (or absence) of replication or caching mechanisms.
Distributed storage. Multiple storage nodes or standalone DFS servers often collectively provide the storage capacity for these file systems. The storage infrastructure may use technologies like RAID (Redundant Array of Independent Disks) or distributed storage frameworks like GlusterFS or Ceph.
Metadata management. A mechanism for managing file metadata, including file names, sizes, permissions, timestamps, and directory structure is core to implementation. It affects whether metadata will be stored and accessed through a centralized metadata server or via a distributed approach across multiple nodes.
File access protocol. Select or design the file access protocol such as NFS (Network File System), CIFS/SMB (Common Internet File System/Server Message Block) that clients will use to interact with the distributed file system to request file operations such as reading, writing, creating, or deleting files.
Replication and consistency. Number of file replicas, methods for maintaining consistency and resolving conflicts when updates are made to replicas, and techniques for handling replication, consistency, and data synchronization across replicas are all important to implementation.
Error handling and recovery. Implement techniques such as error and correction, fault tolerance mechanisms like data replication or erasure coding, and recovery procedures to maintain system availability and recover from failures.
Testing and deployment. Thoroughly test the implemented distributed file system including integration testing, performance testing, and stress testing.
Monitoring and maintenance. Establish and implement procedures and tools to ensure the ongoing performance of the distributed file system. Track system performance, detect anomalies or failures, and apply necessary updates or patches to address any identified issues.
Distributed File System vs Network File System
A distributed file system (DFS) and a network file system (NFS) are two different concepts that address file storage and access in distributed environments. Here are the key differences between distributed file systems and network file systems:
Scope and purpose. A distributed file system (DFS) offers a unified, consistent file storage and access mechanism across multiple machines or nodes in a network. It aims to make the distributed storage infrastructure appear as a single, logical file system to users and applications. A network file system (NFS) is a specific network protocol that allows clients to access files and directories on remote servers. NFS enables remote file access, allowing clients to mount and access remote file systems as if they were local.
Abstraction level. Level of abstraction is another key difference between network file systems and distributed file systems. Distributed file systems operate at a higher level of abstraction, presenting a logical file system that spans multiple physical servers or storage nodes, providing a unified namespace, transparent access to files, and management of file metadata, permissions, and consistency across the distributed environment. The NFS protocol facilitates file-level access to remote file systems. It primarily focuses on providing clients with the ability to perform operations such as reading, writing, and modifying files stored on NFS servers.
Architecture. Distributed File System (DFS): DFS typically involves a distributed architecture where multiple servers collaborate to provide a unified file system. It often includes mechanisms for data replication, fault tolerance, load balancing, and distributed metadata management. NFS can be implemented in different architectural configurations, including a client-server model where clients mount and access NFS shares from remote servers.
Protocols. DFS encompasses a broader concept and can utilize various protocols for file access, such as NFS, CIFS/SMB, or proprietary protocols specific to distributed file system implementation. NFS is a specific protocol that defines the communication between clients and servers for remote file access. It is widely used in Unix and Linux environments, and different versions of NFS exist (e.g., NFSv2, NFSv3, NFSv4).
Use and applications. DFS is suitable for a wide range of distributed computing scenarios where a unified, scalable, and fault-tolerant file system is required such as cloud storage, content distribution networks (CDNs), big data processing, and other distributed computing applications. NFS is commonly used for remote file access in Unix and Linux environments for file sharing, centralized storage, and collaboration in local area networks (LANs) or wide area networks (WANs).
DFS Distributed File System vs Network Attached Storage (NAS) and Local Area Network (LAN)
Network-Attached Storage (NAS) is a storage technology that provides file-level access to centralized storage resources over a network. While NAS shares some similarities with distributed file systems, they are distinct.
NAS focuses on providing shared storage access to clients over a network, typically using standard network protocols such as the Server Message Block (SMB) or Common Internet File System (CIFS) protocol. The Server Message Block (SMB) protocol is a network file sharing protocol used to enable shared access to files, printers, and other resources in a network. SMB is widely used in Windows environments and is the foundation for file sharing and network communication in the Windows operating system.
SMB allows clients to access and interact with the storage resources as if they were locally attached to their systems. NAS offers a centralized storage repository that is accessible to multiple clients.
A Local Area Network (LAN) is network infrastructure that connects devices inside a limited perimeter or geographical region, such as an office building, home, or campus. LANs provide a means for devices to communicate and share resources, including access to distributed file systems and NAS devices.
Connectivity. A LAN provides the physical and logical connectivity between devices within the network. It enables devices, such as computers, servers, NAS appliances, and network switches, to communicate with each other using network protocols like Ethernet.
Network file sharing. In a LAN environment, devices can share files and resources using various protocols that facilitate files, directories, and printer sharing across devices within the LAN, including SMB, NFS, or Apple Filing Protocol (AFP).
Access to distributed file systems. LANs provide underlying network infrastructure for clients to access distributed file systems.
NAS integration. LANs often include NAS devices as centralized storage repositories accessible to clients within the network. NAS appliances are typically connected to the LAN and provide file-level access to shared storage resources. Clients can connect to NAS devices over the LAN using protocols like SMB or NFS to access files and directories stored on the NAS.
Performance and bandwidth. LANs offer high-speed connectivity and ample bandwidth within a local network environment, enabling efficient and fast access to shared files and resources stored on NAS devices or within a distributed file system.
Network security. LANs provide a controlled and secure network environment. Network security measures, such as firewalls, VLANs (Virtual Local Area Networks), access control lists, and encryption, can be implemented within the LAN to protect the confidentiality and integrity of data transmitted over the network.
Object Storage vs Distributed File System
Distributed file systems and object storage are two distinct approaches to storing and accessing data in distributed environments. Here are the key differences in distributed file system vs object storage:
Storage method. In a distributed file system, data is organized and accessed using a hierarchical file structure, similar to traditional file systems, and files and directories are represented and managed through a centralized namespace. Object storage uses a flat address space, where data is organized as objects identified by unique identifiers (e.g., keys), and objects are stored in a flat hierarchy without a traditional file structure.
Access method. DFS provide file-level access, allowing clients to read, write, and modify files using file-based protocols such as NFS or CIFS/SMB. They offer familiar file system semantics, enabling applications to interact with files in a familiar way. Object storage, on the other hand, provides a RESTful API (e.g., Amazon S3 API) to access data. Clients interact with objects individually, using HTTP-based methods like GET, PUT, DELETE, etc., to read, write, and delete objects. Object storage is primarily used for web-scale applications and cloud-native environments.
Metadata management. Unlike distributed file systems which typically manage metadata associated with files, object storage systems manage metadata at the object level. Each object carries its own metadata, including custom-defined metadata and system metadata. Metadata is typically stored alongside the object itself and can be accessed as part of object retrieval.
Data consistency. Distributed file systems offer strong consistency guarantees across file operations. Changes made to files are immediately visible to all clients. Object storage often prioritizes eventual consistency, which may introduce a temporary inconsistency window so changes to objects take some time to propagate across replicas, but allows for higher scalability and performance in distributed environments.
Use cases. Distributed file systems are well-suited for general-purpose file-based workloads, such as traditional file sharing, content management systems, and applications that require file-level access semantics, a familiar interface, and compatibility with existing applications. Object storage is designed for large-scale, unstructured data, often used in cloud-native and web-scale applications. It is commonly employed for storing and serving multimedia content, backups, archives, data lakes, and other data-intensive use cases.
Clustered File System vs Distributed File System
Both designed to handle file storage and access in distributed computing environments, cluster file systems vs distributed file systems have distinct characteristics and usage scenarios:
Architecture. A cluster file system is specifically designed for clustered computing environments where its file system can be simultaneously accessed by multiple interconnected servers or nodes that work together as a cluster. Distributed file systems employ a decentralized architecture where file data and metadata are distributed across multiple nodes or servers, ensuring scalability and fault tolerance.
Replication/awareness. Cluster file systems are aware of the cluster topology and the presence of multiple nodes. They often incorporate cluster-awareness features, such as load balancing and failover mechanisms, to ensure optimal performance, fault tolerance, and high availability within the cluster. Distributed file systems often utilize replication mechanisms to ensure data availability and fault tolerance. File data may be replicated across multiple nodes for redundancy, while metadata is replicated or distributed for consistency and availability.
Performance and scalability. Cluster file systems are optimized for high-performance computing environments, where parallel processing and shared access to data are essential. They are designed to provide low-latency access to files and high throughput to support demanding workloads. A distributed file system is designed to handle file storage and access across a distributed network, which may span multiple clusters or independent nodes. It allows files to be stored and accessed across different machines, even geographically dispersed ones.
Shared storage, locking, and network transparency. All nodes in the cluster typically have direct access to a shared storage resource, such as a disk array or a storage area network (SAN), so they may access and modify files concurrently. They typically employ shared file locking mechanisms to ensure that multiple nodes can modify files without conflicts or inconsistencies. Distributed file systems are designed to operate over wide area networks (WANs), allowing geographically dispersed clients to access files. They often optimize for efficient data transfer and latency reduction across the network. Distributed file systems aim to provide network transparency, making the distributed storage infrastructure appear as a single, unified file system to clients.
Hadoop Distributed File Systems
The Hadoop Distributed File System (HDFS) is a distributed file system and a core component of the Apache Hadoop ecosystem. HDFS is designed for storing and processing large-scale data in a distributed computing environment. It serves as the primary storage system for Hadoop clusters.
Architecture. HDFS employs a controller/worker architecture. The NameNode serves as the controller node and acts as the central coordinator of the file system. It manages the file system namespace, metadata, and client operations. DataNodes are worker nodes responsible for storing and managing the actual data. They are distributed across the cluster and store data in the form of blocks. DataNodes handle read and write operations requested by clients and replicate data blocks for fault tolerance.
Storage. HDFS breaks down files into fixed-size blocks, with a default size of 128MB, larger than typical file system block sizes to optimize large-scale data processing. Each block is replicated across multiple DataNodes for fault tolerance.
Availability and reliability. HDFS provides automatic replication of blocks to ensure data availability and reliability. By default, each block is replicated three times across different DataNodes. The replication factor can be configured to meet the desired fault tolerance and data redundancy requirements.
Access. Clients interact with HDFS through the Hadoop API, command-line interface (CLI), or third-party tools. They communicate with the NameNode to perform file system operations such as file creation, deletion, or reading. When a client wants to read a file, it sends a request to the NameNode, which responds with the locations of the relevant data blocks. The client can then directly read the data from the corresponding DataNodes. Write operations follow a similar process, with the client communicating with the NameNode to obtain the DataNodes where the data should be written.
Data locality. HDFS optimizes data processing by promoting data locality. It tries to schedule computation tasks closer to the nodes storing the relevant data. This reduces network transfer and improves performance by minimizing data movement across the cluster.
Fault tolerance and data recovery. To ensure high availability, HDFS provides mechanisms for maintaining multiple standby NameNodes. If the active NameNode fails, one of the standby NameNodes takes over to continue the file system operation. If a DataNode fails, the NameNode detects the failure and replicates the lost blocks onto other available DataNodes to maintain the desired replication factor. The system also includes mechanisms for detecting and handling corrupted blocks.
Scalability and cluster expansion. HDFS is designed to scale horizontally. New DataNodes can be easily added to the cluster, and HDFS automatically redistributes data across the newly added nodes to balance the data distribution. HDFS is optimized for large-scale data storage, batch processing, and parallel computing. It provides fault tolerance, data reliability, and scalability, making it suitable for big data processing and analytics workloads in Hadoop clusters.
Distributed File System Replication
Distributed file system replication is the process of creating and maintaining multiple copies of data across multiple nodes or servers in a distributed file system. The goal of replication is to enhance data availability, fault tolerance, and performance by ensuring that data is stored redundantly across multiple locations.
Redundant data copies. DFS replication involves creating multiple copies of data and distributing them across different storage nodes or servers. Each copy is typically stored on a different physical machine or within a different data center to ensure redundancy and fault tolerance.
Fault tolerance. Replication provides fault tolerance by allowing the system to continue functioning even if one or more storage nodes fail, allowing clients to access replicated copies of the data from other available nodes.
Data consistency. Updates or modifications should be reflected in all other replicas to ensure data integrity. Different replication consistency models, such as strong consistency or eventual consistency, determine how updates are propagated and synchronized across replicas.
Replication factors. Distributed file systems typically allow administrators to configure the replication factor, which defines the number of replicas created for each data block or file. Common replication factors include 2x (two replicas), 3x (three replicas), or higher, depending on the desired level of fault tolerance and data redundancy.
Replication strategies. There are various replication strategies employed in distributed file systems, depending on the specific requirements and design choices. Full replication involves replicating each data block or file completely across multiple nodes. This strategy ensures complete redundancy but consumes more storage space. Selective replication involves replicating only specific data blocks or files based on factors such as access patterns, popularity, or importance. This strategy optimizes storage utilization but may selectively replicate data based on specific criteria.
Erasure coding. An alternative to full replication, erasure coding techniques distribute encoded fragments of data across nodes, using fragments to reconstruct the original data. Erasure coding comparatively reduces storage overhead while maintaining fault tolerance.
Replication management. Distributed file systems include mechanisms to manage replication, such as monitoring the health of storage nodes, detecting node failures, and initiating replication or recovery processes when needed. The system continuously monitors and adjusts the replication topology to maintain the desired replication factor and data redundancy.
Deadlock in Distributed Systems
In distributed deadlock systems, the “deadlock” refers to a situation where multiple processes or components are unable to proceed because they are waiting for each other to release resources or take specific actions. Deadlocks can occur when there is a circular dependency among processes or components, leading to a system-wide impasse. Here risk factors that make them more likely to arise in the DFS setting:
Resource dependency. Deadlocks arise when multiple processes or components compete for shared resources, such as locks, files, communication channels, or distributed services. If each process holds resources that are required by other processes and all processes are waiting for resources held by others, a deadlock occurs.
Circular wait. Deadlocks involve a circular wait condition, where each process in the cycle is waiting for a resource held by another process in the cycle. The circular wait condition creates a situation where no process can proceed because each process depends on a resource held by another process.
Lack of progress. Deadlocks cause a lack of progress in the system, as processes or components are unable to move forward or complete their tasks. The deadlock state prevents the execution of critical sections of code, leading to system stalling or freezing.
Distributed nature. Deadlocks can occur due to the distribution of resources and the need for coordination among multiple nodes or components. Deadlocks can also arise from network communication delays, inconsistent resource allocation, or the failure of coordination mechanisms across distributed components.
Detection and resolution. Detecting and resolving deadlocks in distributed systems can be challenging due to the complexity of the system and the lack of a central authority. Techniques for deadlock detection and resolution include resource allocation graphs, distributed deadlock detection algorithms, and approaches such as resource preemption or process termination to break the deadlock.
Prevention and avoidance. Designing distributed systems with proper resource management and avoidance strategies can help prevent deadlocks. Techniques such as resource ordering, deadlock detection with timeouts, and careful resource allocation policies can be employed to minimize the occurrence of deadlocks.
Trade-offs. Dealing with deadlocks requires trade-offs between system performance and safety. Strict prevention mechanisms can be resource-intensive and impact system efficiency, while more relaxed avoidance or detection strategies may allow deadlocks to occur but provide means for recovery or resolution.
Distributed File System Examples
Distributed file systems have a wide range of use cases across various industries and applications, such as large-scale storage systems, cloud storage, content distribution networks (CDNs), and distributed file-sharing platforms. Here are some more common distributed file system examples:
Big data analytics. Storing and processing large volumes of data and big data analytics platforms are among the more common distributed file systems concepts and examples of DFS in action. The Hadoop Distributed File System (HDFS), a core component of the Apache Hadoop ecosystem, is used for distributed storage and processing in big data analytics.
Distributed file systems in cloud computing. Cloud distributed file systems provide scalable, reliable storage solutions for cloud-based applications and file sharing platforms. For example, Google Cloud Storage offers a distributed file system for cloud environments with object storage and high scalability and availability. And Amazon S3 (Simple Storage Service) is a distributed object storage service that provides reliable, scalable storage for cloud-based applications.
Content distribution networks (CDNs). CDNs use distributed file systems to deliver content efficiently to users worldwide. Examples include: Ceph, a distributed file system commonly used in CDNs for scalable and fault-tolerant content delivery, and Fastly, a CDN that utilizes distributed file systems to store and distribute content to end users globally.
High-performance computing (HPC). Distributed file systems support data-intensive scientific computing in HPC environments. Examples include: Lustre File System, a popular distributed file system used in HPC clusters for high-performance data storage and access, and BeeGFS (formerly FhGFS), a parallel file system designed for high-performance computing and demanding I/O workloads.
Media streaming and broadcasting. Another example of distributed file system applications is streaming platforms and broadcasting systems that store and deliver large media files efficiently. This includes GlusterFS, is a distributed file system often utilized in media streaming applications to store and serve media content, and OpenStack Swift, a distributed object storage system used in media broadcasting and streaming for storing and delivering media assets.
Data archiving and backup. Distributed file systems used for data archiving and backup include EMC Isilon, a distributed file system solution designed for scalable storage and efficient data backup and archiving, and IBM Spectrum Scale (formerly GPFS), a high-performance distributed file system used for large-scale data storage, backup, and archiving.
Advantages of Distributed File System
There are several benefits of distributed file systems that might prompt an organization to consider a DFS solution for its environment, but most reasons for selecting these options boil down to a need to access the same data from multiple locations. This need could be due to requiring support for multiple sites processing the same data. An example of a team with such a need would be a multi-site engineering team that has compute resources local to their environment and that has a group of engineers who all participate in different phases of engineering a system while using the same data. It could also be due to cloud bursting, where workloads move from on-premises to in-cloud or even to other AZs within a cloud to gain access to more processing power. Finally, another example might include any situation in which one wants to utilize a hybrid cloud solution that requires access to the same data. All these can benefit from the use of a DFS.
Yes, these capabilities could all be accomplished in some other way, such as copying/moving data from one site/cloud to another. But that takes planning, time, and manual, error-prone procedures to make it happen. A DFS can do all of this for you–automatically–without any of the pain.
Disadvantages of Distributed File System
If data resides on cloud storage and is consumed elsewhere, cloud egress charges may be significant. This cost can be mitigated somewhat by data reduction techniques and the fact that DFS will move only data that is being accessed, but that may still leave a significant egress expense.
While DFS systems can cache data to improve local access, none can defeat the speed of light. That is, the access to the first non-cached byte of data may take an inordinate amount of time depending on how far it is from where it is being accessed. DFS solutions can minimize this overhead by overlapping cached data access while fetching the next portion of data, but doing this will not always mask the network latency required to access a non-cached portion of the data.
DFS systems can sometimes be complex to deploy. With data that can reside just about anywhere with hosts that can access all of it from anywhere else, getting all of this to work together properly and tuning it for high performance can be a significant challenge. Vendor support can help considerably. DFS vendors will have professional services that can be used to help deploy and configure their systems to get them up and running in a timely fashion. Also, they will have sophisticated modeling that can tell them how much gateway, metadata, and storage resources will be required to support your performance.
WEKA’s Revolutionary DFS for Enterprise
It all boils down to this: DFS systems offer global access to the same data that is very difficult to accomplish effectively in any other way, especially when you have multiple sites, all computing with and consuming the same data. DFS systems can make all of this look easy and seamless, without breaking a sweat. So, if you have multiple sites with a need to access the same data, a distributed file system can be a godsend.
WEKA is helping many of the world’s leading enterprises and research organizations to tame and harness their unstructured data and performance-intensive workloads by overcoming the limitations of their legacy data infrastructure so they can create and innovate without limits. The core of the WEKA Data Platform is WekaFS: a software-based parallel distributed file system with an advanced architecture that solves complex data challenges and supports demanding next-generation workloads like artificial intelligence (AI) and machine learning (ML) at scale across on-premises, edge, cloud, hybrid, and multi-cloud environments. Learn more about WEKA’s capabilities and recognition as Visionary in Gartner Magic Quadrant for Distributed File Systems.
Additional Helpful Resources
Lustre File System Explained
General Parallel File System (GPFS) Explained
BeeGFS Parallel File System Explained
FSx for Lustre
What is Network File System?
Network File System (NFS) and AI Workloads
Block Storage vs. Object Storage
Introduction to Hybrid Cloud Storage
Learn About HPC Storage, HPC Storage Architecture and Use Cases
NAS vs. SAN vs. DAS
Isilon vs. Flashblade vs. WEKA
5 Reasons Why IBM Spectrum Scale is Not Suitable for AI Workloads
Redefining Scale for Modern Storage
Distributed Data Protection
Recommended Resources



Related Assets
-
Practical Strategies for Navigating the Memory Shortage

Practical Strategies for Navigating the Memory Shortage
-
The Impact of Storage on the AI Lifecycle

The Impact of Storage on the AI Lifecycle
-
The Buyer’s Guide to AI Storage

The Buyer’s Guide to AI Storage