What are modern workloads?

Technology has changed dramatically in the last 20 years. High speed connectivity has become a commodity, and compute now works at mind-blowing speeds. Just think about how quickly an autonomous vehicle processes and reacts to potential accident situations–it’s done in milliseconds. Data is being generated all around us: street cameras, shopping centers, office buildings, your car, your phone, your watch, your family’s personal Nest.
Just as our personal and consumer data speeds and quantities have changed, so has the enterprise workload changed–from client-server technologies and relational databases to machine and deep learning processed by mini-edge processors or supercomputers in the core. In the next couple of minutes let’s define what modern workloads are and identify the key elements that characterize them.
Volumes of Unstructured Multi-format Data
One of the hallmarks of modern workloads is that they use tons of unstructured data–tons!–all coming from a myriad of different sources, dressed up in different formats, and hailing from different types of locations.
A real-world example of a modern workload in the realm of Life Science is that of Genomics England or GEL for short. GEL needed a solution to support the UK National Health Service 5 Million Genomes Project in which a team of over 3,000 researchers was tasked with sequencing 5 million genomes from NHS patients with rare diseases using the DNA data acquired from NHS for medical research. That is a daunting task. When was the last time you were asked to deliver 5 million of anything? Early estimates from GEL predicted that the data would grow to over 140 Petabytes by 2023, and that estimate is considered to be conservative.
Another example is within the realm of autonomous vehicles. Think of how many images companies like WeRide or TuSimple need to collect in order to train their models to be able to identify a stop sign, a crosswalk, another vehicle, or a living obstacle–be it human or of the pet variety. AI systems for autonomous driving involved continuous processes of improvement, using massive globalized data sets. All image recognition is of the utmost importance to vehicles’ occupants and to the property and people around them, so the more data, the more tests, and the greater success for training models–the better.
Another example is manufacturing, where data is gathered from millions of machines for manufacturing analytics, using data from various operations, events, and technologies in the manufacturing industry to ensure high product quality, increased performance and production yield, reduced manufacturing costs, and optimized supply chains–all with the goal of achieving actionable insights in real time.
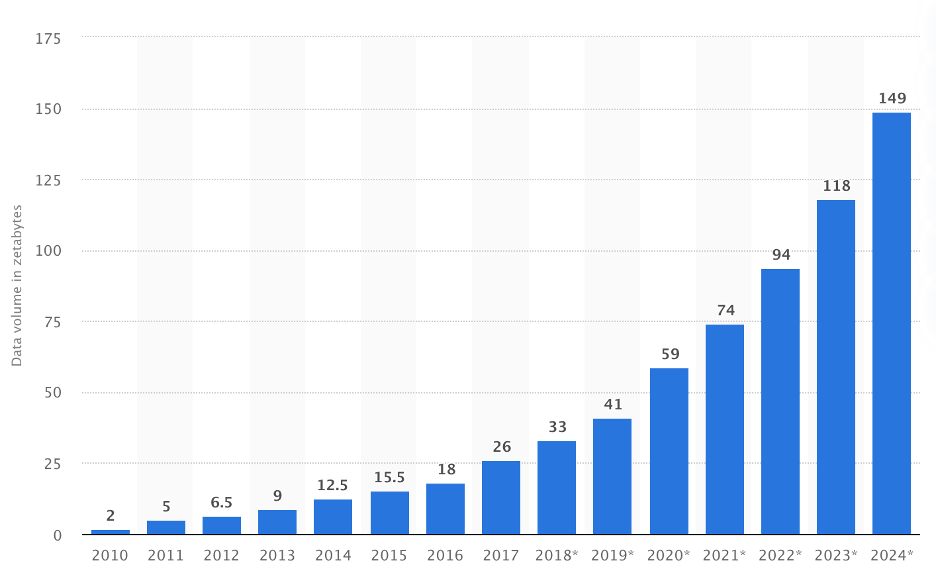
According to Statista, data volumes from 2021 to 2024 are expected to grow at a compound annual growth rate (CAGR) of 26 percent and reach 149 Zetabytes by 2024.
But it’s not just the volume of data that has changed. Historically, data was not as widely available as it is today, so sources were limited. These days data is everywhere, so you can enrich and cross-reference the data through multiple sources. Financial institutions, for example, develop sophisticated fraud detection models that combine your mobile device location with your credit card purchases or analyze your mouse movement and keystrokes to determine if the person logging into the account is a fraudster or a legit user.
Similarly, predictive maintenance models combine unstructured logs with sensor data. Know Your Customer banking practices validate data from multiple sources such as data hubs (e.g., Lexis Nexis) with social media, black lists, and other sources.
Data these days comes from multiple sources and in different formats. Historically, each workload used different formats, so data silos didn’t limit the results. These days it’s very common to store all data under a single umbrella, such as a data lake. and give all workloads access to the data, removing silos. Support for the different formats, given no silos, is not an easy task.
Finally, relational databases were very common 15-20 years ago. Each piece of data would be stored in a row and column, and searching and filtering through the data would be easy given the technology and compute power of that time. Today’s technology and compute power allows us to perform the same tasks on non-relational datasets, and in recent years we’ve seen a surge in unstructured data as a result of that. We’ve also seen a shift in the sources of data. The ability to handle unstructured data and the emergence of Internet Of Things (IOT) and connected devices led to a surge in self-generated data. According to a 2020 study by Igneous Systems, North America’s data-centric enterprises are working with massive, difficult-to-manage volumes of unstructured data. Most (59 percent) of the respondents report managing more than 10 billion files, with an average annual growth rate of 23 percent. Respondents of the survey reported that 55% of their data is generated by machines.
Containerized Applications
The introduction of containers allows organizations to spin up (and down) units of software quickly. This ability allows organizations to better utilize their resources, as multiple containers can share the same computational resources and the the same operating system to speed up the development cycle, as multiple developers can work in parallel quickly, getting access to the environment they need without the need for a lengthy spin-up process or the need to wait for resources to become free.
That also means that today’s workflow needs to be much more independent and “contained.” The concept of microservices emerged: a piece of software that consists of a number of loosely coupled services with standard interface servicing one another.
Containers tend to be more lightweight and independent, and they allow for the spinning up and tearing down of runtime environments in a matter of seconds.
Accelerating Time to Insights
With the ability to store volumes of data and the introduction of machine learning and deep learning models to analyze these volumes, most industries now realize the value of data and how it can help them to become more competitive. In a survey we recently conducted, the majority of organizations reported “competitive advantage” and “introduction of new products” as the two main drivers behind their AI and ML initiatives. If those are, indeed, the main objectives, then there’s a lot at stake, and time-to-market is key. Think about the business impact of an algo-trading investment firm that releases a new model before other firms do or the impact of one car company achieving higher levels of autonomous driving ahead of another. Data is the new oil and faster time to insight is the competitive edge that companies need to make data a winning strategy.
In the next post we’ll discuss the requirements of modern data architecture to support the characteristics of modern workloads that were just described.
Additional Helpful Resources
Six Mistakes to Avoid While Managing a Storage Solution
Genomics and Cryo-EM Workflows in Life Sciences
What is Data Orchestration? A Guide to Handling Modern Data
Popular Blogs From WEKA



Related Assets
-
See NeuralMesh in Action

See NeuralMesh in Action
-
The AI Factory Blueprint: Designing for Scalable, Efficient Inference

The AI Factory Blueprint: Designing for Scalable, Efficient Inference
-
The Buyer’s Guide to AI Storage

The Buyer’s Guide to AI Storage