Kubernetes for AI/ML Pipelines Using GPUs

Introduction to Modern AI Workloads
As customers embark on their Digital Transformation journeys where they are looking to reduce their time to market and improve productivity, and where they are launching new business models that leverage Artificial Intelligence (AI), Machine Learning (ML) and Deep Learning (DL), they increasingly try to adopt technologies like containers, NVMe flash, and GPUs.
AI/ML/DL workloads often require processing massive amounts of unstructured data, including images and/or videos. These workloads run iteratively until the results are accurate; hence, completion time of each workload is key. Graphical Processing Units (GPUs) significantly accelerate the time to completion of these workloads. Here’s how:
- GPUs can perform multiple, simultaneous computations
- GPUs are highly efficient at these types of calculations
- GPUs have a massive number of cores that can be used efficiently in parallel
Challenges Using Kubernetes for AI & ML with GPUs
Containers became the popular AI/ML deployment model due to their light weightedness, their immutability and portability, and their agility with orchestration provided by Kubernetes.
However, we see three challenges when using container and Kubernetes with GPU resources:
- The existing schedulers were not designed for HPC applications, which are stateful and batch oriented, especially when performing AI/ML training.
- Maximizing expensive GPU utilization while staying aware of the training and inference phases within the data pipeline can be difficult.
- Meeting the need for scale-out, high-performance storage to reduce epoch times, handle mixed workloads, and handle lots of small files (LOSF) and their metadata can be equally challenging.
Addressing GPU Utilization with Run:AI Virtualization and Scheduling
By abstracting workloads from underlying infrastructure, Run:AI creates a shared pool of resources that can be dynamically provisioned, enabling full utilization of expensive GPU resources and, thus, addressing challenge #1 and challenge #2.
Part of the issue in getting AI projects to market is due to static resource allocation holding back data science teams. There are many times when those important and expensive compute sources are sitting idle, while at the same time other users that might need more compute power (to run more experiments) don’t have access to available resources because they are part of a static assignment. To solve that issue of static resource allocation, Run:AI virtualizes those GPU resources, whether on premises or in the cloud, and lets IT define by policy how those resources should be divided.
Additionally, there is a need for a specific virtualization approach for AI and actively managed orchestration and scheduling of those GPU resources, all while providing the visibility and control over those compute resources to IT organizations and AI administrators.
Addressing High-Performance Stateful Storage with WEKA
Virtualization and optimal utilization of GPU resources are only as effective as the fastest access to the datasets. High-performance storage makes virtualization of GPUs very effective, while furthering scale, reducing epoch times, and lowering inference latency. Additionally, each phase of the data pipeline needs mixed workload handling as shown below.
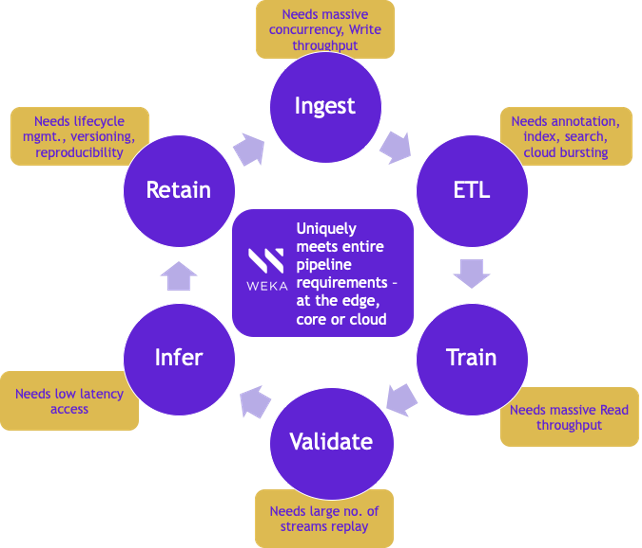
WEKA with its mixed workload capability, high performance even with containerized deployments, and ability to handle LOSF in a single directory is uniquely positioned to meet these requirements.
WEKA Solves Storage Persistence Challenges with its CSI Plug-in
Using the WEKA Kubernetes CSI plugin organizations now have increased flexibility in how and where they deploy containers, all while delivering local storage performance and low latency. In fact, throughout the system WEKA delivers the speed-to-market required of an AI-first solution.
The WEKAS CSI plugin is deployed using a Helm Chart, along with the POSIX agent on Kubernetes worker nodes. WEKA supports volume provisioning in both the dynamic (persistent volume claim) and static (persistent volume) forms with its own storage class. It also supports ReadOnlyOnce, ReadOnlyMany, ReadWriteOnce, and ReadWriteMany access modes.
WEKA thus, addresses the shareability, acceleration, and portability of challenge #3 by providing stateful, reliable storage. WEKA also allows seamless deployment on-premises and easy migration to the cloud, all while meeting the requirements of high performance, mixed-workload handling, and low latency.
How Does the Joint Solution Work?
The solution is available as a WEKA AI reference architecture, for easy consumption, as shown below –
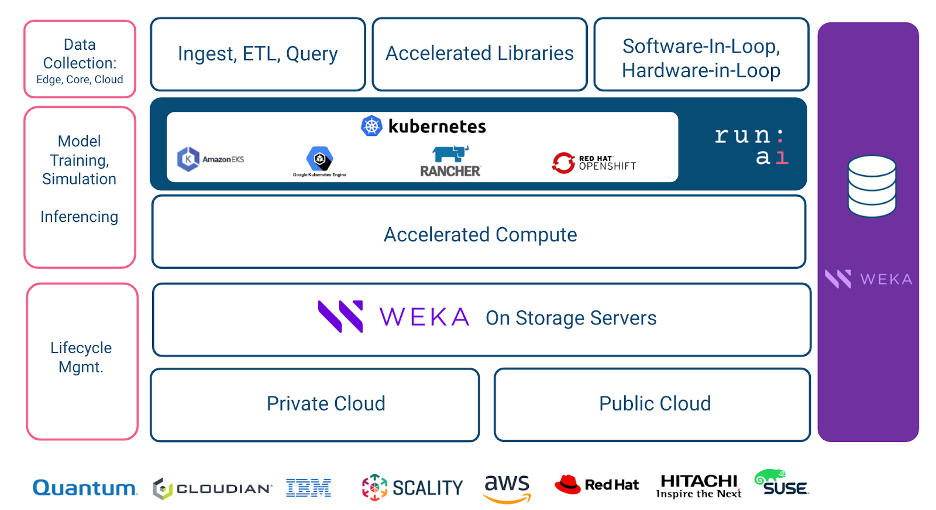
Researchers submit jobs and then Run:AI’s dedicated batch scheduler. Running on Kubernetes provides an elegant solution to simplify what is often a complex scheduling process. Jobs are queued, and prioritization policies are applied to automatically and dynamically run many jobs from many users at one time. Run:AI customers make use of the platform for compute-intensive workloads such as multi-node training, as well as fractional usage of a GPU, particularly for inference use cases and for when researchers interactively prototype their models. Researchers can leverage the WEKA CSI Plugin and dynamically mount provisioned WEKA volumes to their jobs through the Run:AI system.
Achieving Persistent Performance of Containerized AI Applications with WEKA and Run:AI
Speed is critical in AI; data science initiatives are launched in order to solve some of the most pressing business questions. When companies want to run many experiments in parallel–with fast access to datasets located on centralized storage utilizing limitless compute resources–they can look to Run:AI and WEKA for solutions. Together, high-performance storage and optimization of GPU resources enables AI to scale and ultimately to succeed.
Additional Helpful Resources
Kubernetes Storage Provisioning
Accelerating Containers with a Kubernetes CSI Parallel File System
Stateless vs. Stateful Kubernetes
How to Rethink Storage for AI Workloads?
Create persistent storage for your containerized applications
Using Weka Kubernetes CSI plugin
Popular Blogs From Shailesh Manjrekar


Related Assets
-
Scaling Smart: Future-Proofing Your AI Infrastructure

Scaling Smart: Future-Proofing Your AI Infrastructure
-
Gorilla Guide to High Performance Data in the Cloud

Gorilla Guide to High Performance Data in the Cloud
-
Turbocharge AI Workloads with an AI-Native Data Platform

Turbocharge AI Workloads with an AI-Native Data Platform
