AI Tokenomics: More Than Talk – See Results from Our Labs

Two weeks ago, we blogged about the future of AI token economics (aka “tokenomics”) and how optimizing memory and storage can unlock unprecedented efficiencies. We explored how DeepSeek’s breakthrough in token processing showcasing a 26x improvement—and reducing the time to first token (TFFT) for a 128K-token prompt from 13 seconds to 0.5 seconds—is creating a new global focus on AI efficiency.
We talked about how WEKA has been working on similar innovations, but let’s move beyond the discussion and show you what WEKA has been testing in our own labs to drive radical tokenomics. To show the benefits of extending GPU high-bandwidth memory with ultra-fast storage, we put NeuralMesh™ to the test, leveraging NVIDIA Magnum IO™ GPUDirect Storage (GDS) and a high-performance 8-node WEKApod and saw some dramatic token processing improvements, including a 41x improvement in token prefill time for 105,000 AI tokens without compression as well as significant benefits at short context lengths as well.
The Challenge: AI Token Processing and Memory Limitations
Let’s quickly review why inference at scale needs innovation. A fundamental limitation in modern AI inference is the amount of memory available–GPUs process vast amounts of data in parallel, but the memory available per GPU is fixed. As models grow in complexity and require longer contexts, their memory footprint expands beyond what a single GPU can handle. This results in inefficiencies where GPUs are memory-starved, causing significant bottlenecks in AI token generation. This is a particular challenge during the decode phase of Large Language Models (LLMs), which are memory-bound, requiring fast data retrieval to process input prompts efficiently.
Additionally, GPUs cannot directly scale their memory independently of compute. When additional memory is needed, the only solution is to add more GPUs, which increases costs without proportionally improving performance. Many AI workloads exhibit a mismatch in resource utilization, leading to 60% idle GPU time as excess computational power goes unused simply because more memory is needed.
The challenge is clear: How do we decouple GPU compute from memory limitations to maximize efficiency and reduce costs?
Tackling AI’s Biggest Challenges at Scale
At WEKA, we are working on solving some of the largest challenges of AI at scale, particularly in AI inference and training. Large-scale AI training requires massive computational resources and efficient data pipelines to manage growing datasets and complex model architectures. The ever-increasing demand for high-performance storage and seamless GPU utilization drives the need for innovative solutions to minimize bottlenecks. Deploying AI models efficiently at scale comes with its own set of hurdles. As noted, inference workloads often struggle with latency, memory constraints, and the ability to dynamically adjust to workload demands. As models grow larger and more complex, ensuring that AI inference pipelines can handle increasing context lengths without excessive delays is critical.
One of the biggest challenges emerging in AI inference is the impact of expanding context lengths on compute requirements. As techniques like reasoning tokens increase, models must process significantly longer sequences, putting additional strain on memory and compute resources.
In our testing with LLaMA3.1 70B with no quantization, we observed that a large 100,000-token prompt can take ~24 seconds just to prefill—essentially initializing the model before generating any output. Many existing inference systems discard this prefill data after use, resulting in unnecessary computational overhead every time the model is run.
What DeepSeek demonstrated is a method to retain the KV cache and reload it when needed, dramatically reducing redundant computation. This approach, already adopted by other labs, offers significant performance and cost benefits. However, while many proprietary solutions exist, our goal at WEKA is to bring this same capability to the enterprise in an open and scalable way.
The key challenge now is speed—how quickly can we reload and apply this KV cache at scale? This is where WEKA’s leadership in high-performance storage and data management comes into play. Our approach ensures that AI workloads can retain, retrieve, and reuse inference data with minimal latency, unlocking new efficiencies for enterprise AI deployments.
The WEKA Vision: Purpose-Built for AI
WEKA is uniquely positioned to solve many of these challenges. Unlike general-purpose storage solutions that aim to do everything adequately, WEKA is laser-focused on AI workloads, ensuring that every optimization is tailored for performance, scalability, and efficiency.
From a data processing perspective, WEKA has the capability to align reads and writes into GPU memory (via GDS) directly to the NIC closest to the GPU, and extract every last bit of performance by reducing unnecessary data movement and latency. This allows for a more efficient pipeline that keeps AI models fed with data at unprecedented speeds. And, we designed our architecture to break up I/O into highly parallel streams, ensuring that AI workloads can access and process data faster than ever before.
Beyond just optimizing storage, WEKA also has the expertise to work directly on inference engines. To that end, we set out to validate how extending GPU memory to ultra-fast storage can dramatically improve token processing efficiency. Our tests demonstrate that by combining high-speed storage with intelligent data management, AI workloads can achieve both higher throughput and lower inference costs—unlocking new possibilities for enterprises looking to scale their AI infrastructure.
WEKA’s Proof of Concept: Pushing Tokenomics Even Further
To validate how extending GPU memory to ultra-fast storage can dramatically improve token processing efficiency and to highlight the power of the WEKA architecture, we ran multiple tests with varying numbers of tokens and configurations to see what spectrum of outcomes we could drive.
- NVIDIA DGX H100
- 8-node WEKApod with PCIe Gen 5
- NVIDIA Quantum-2 QM9700 64-port NDR 400Gb/s InfiniBand switches
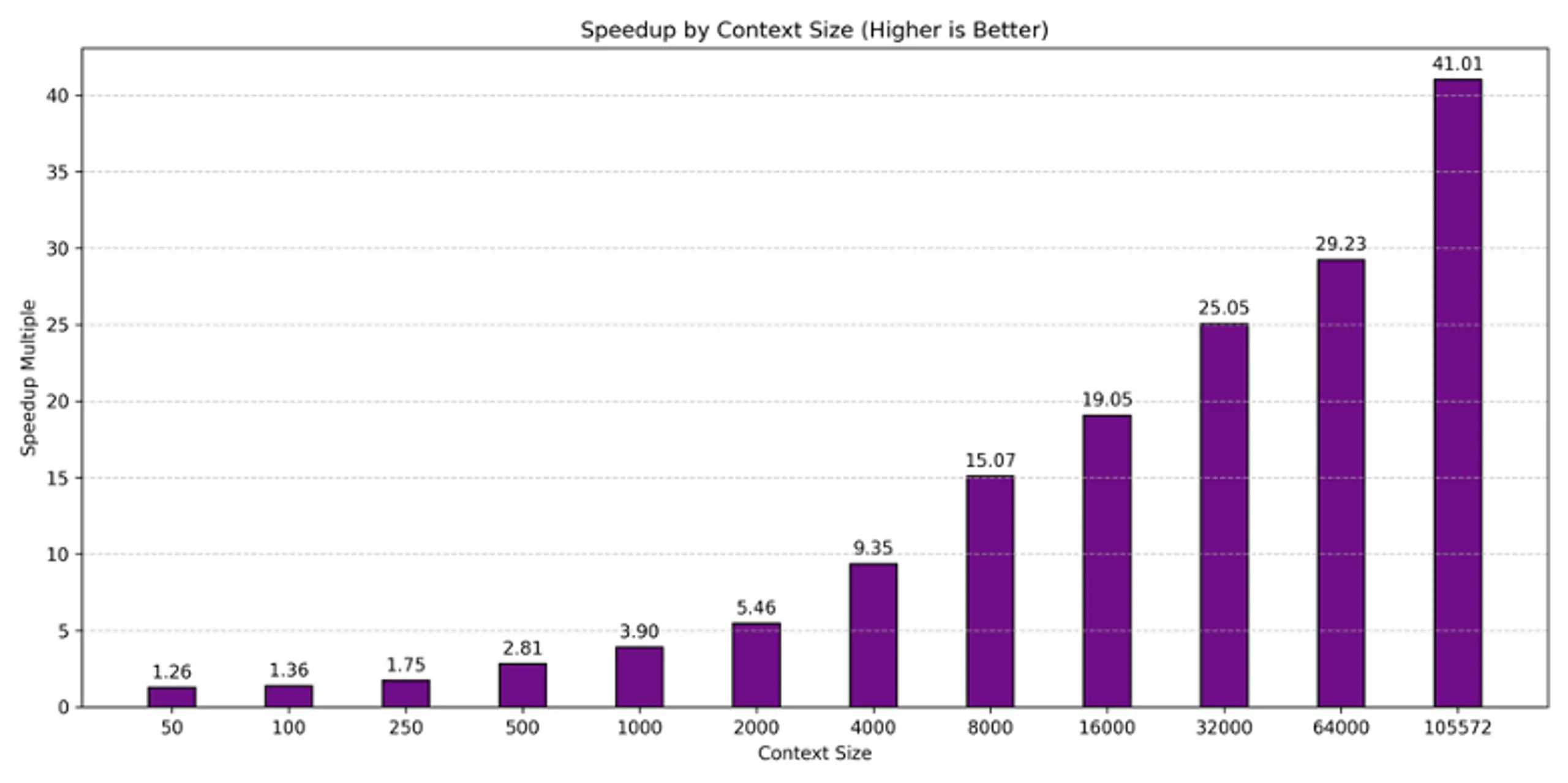
Our tests demonstrated a staggering 41x reduction in prefill time on LLaMA3.1-70B, dropping from 23.97 seconds to just 0.58 seconds. This is a massive improvement, effectively eliminating one of the biggest bottlenecks in inference workloads. Of the 0.58 seconds, the data transfer time was less than 0.2s, so this has the potential to be reduced even more by reducing the overhead of the inference session in the engine. This is a level of efficiency we have not seen from other interference optimization work. As AI models continue to expand their context lengths, this is needed to ensure that inference workloads are not just scalable, but also significantly more efficient at every step.
Notably, we conducted this test without compressing the KV Cache or using any quantization, ensuring that GPUs were fully dedicated to inferencing work. Many of our enterprise customers prioritize achieving the highest accuracy possible, and this approach guarantees that precision remains uncompromised. What makes this even more compelling is that we also see huge prefill time improvements with much smaller context sizes, even with context lengths as small as 50 tokens.
Key Takeaways: Why Tokenomics Matters for Generative AI
Regardless of the specific token count, one thing is clear—these optimizations drive enormous efficiency gains for GPUs. Saving 24 seconds of compute time per request frees up GPUs to generate more output tokens instead of waiting for prefill data. And when you have fast model load time over GDS, fast AI checkpointing of training, and now fast resume of inference jobs, you can now blend or pool your training and inference and dynamically switch between the two. Consolidating workloads on the same infrastructure reduces hardware sprawl, simplifies management, and ensures maximum utilization of AI resources, improving both cost efficiency and operational flexibility.
The Future of AI Tokenomics
As AI adoption grows, optimizing tokenomics will become a competitive necessity. Businesses that fail to drive down token processing costs risk being left behind. With innovations in storage, caching, and latency reduction, WEKA is at the forefront of making AI more scalable, cost-efficient, and accessible on-premises or in any public cloud. WEKA is actively working to productize these optimizations together with our design partners, ensuring that enterprises can leverage storage-accelerated AI to improve token processing efficiency at scale.
Learn more about WEKA and the evolving landscape of AI tokenomics.
What's Next



Scale Production AI Faster with NeuralMesh
Your models aren't slow. Your data is. Fix AI bottlenecks with high-throughput infrastructure.