WEKA Autoscaling: Bringing Elasticity to Cloud Storage

In a recent blog we discussed how elasticity is one of the most important properties of cloud computing. Elasticity is central to making the economics of cloud computing work when compared to traditional on-premises data centers. In summary, the ability to access new resources, scale out and shrink (known as autoscaling) the resources deployed, and shift resources across regions and geographies on demand. In this blog we will dive deeper into the autoscaling feature of cloud computing as it relates to cloud storage.
The autoscaling feature for compute and most databases is available across all the major cloud vendors and is an essential tool to maintaining a predictable and cost-optimized environment for cloud computing (for example AWS Auto Scaling, Azure VM Scale Sets). Autoscaling allows organizations to scale compute resources to meet specific and predictable performance objectives. When the autoscaling limits are hit, new resources are spun up (maintaining predictable performance) or shut down (saving cost) to adhere to the performance limits.
Legacy storage infrastructure vendors frequently talk in terms of scaling using a very narrow definition based on their design. Traditional infrastructure building blocks either scale up or scale out. Scale-up architectures add more capacity to the storage infrastructure but do not add any performance. Scale-out architectures add more performance and some limited capacity. It is not possible to have both scale-up and scale-out together, forcing administrators to choose between one architecture or the other for their core building blocks. Of course, it merits mentioning that none of the legacy architectures support scaling back down. In part this is driven from the fact that physical infrastructure has to be purchased to begin with so it is already a sunk cost. However, and more importantly, the systems have not been designed with scaling down in the design, making it impossible to transfer the capability to the cloud.
Amazon pioneered the concept of autoscaling to allow customers to better manage peaks and troughs in their compute resource requirements and applied it across the Elastic Cloud Compute (EC2) service. Autoscaling is now widely available across all the major clouds.
Now imagine if we could apply the benefits of autoscaling to the storage infrastructure. An autoscaling storage infrastructure would match the application performance and capacity requirements in the same way as compute resources. Unfortunately though, the cloud storage infrastructure has predominantly followed the traditional on-premises model with the same limitations on scale-up and scale-out. Changes to the storage infrastructure require human intervention to change the environment. Because cloud vendors leveraged legacy file and block storage technologies to create a cloud solution, all the scaling problems of legacy storage came with them. For example, the only way to satisfy bursty workloads on-premises is to over-provision infrastructure to meet peak demands; the same applies to the cloud. Other common on-premises strategies such as multiple copies of exactly the same data just to maintain a certain service level also exist in the cloud. Adding more performance on-demand is not possible with current cloud architectures, as cloud storage performance is tightly coupled with cloud storage capacity. More performance means adding more capacity, even if it is not required. The corollary is more performance will incur unwanted costs from wasted resources. The only cloud solution that easily scales capacity is the object storage infrastructure, (such as Azure Blob or AWS S3), however most enterprise applications cannot communicate over S3.
Scaling Performance
A well-architected data platform leverages the existing cloud infrastructure and utilizes it in a way that allows for autoscaling of the underlying storage infrastructure. By leveraging multiple EC2 instances with local storage a single pool of high performance storage is created. This scale-out architecture evenly distributes data and metadata across all the EC2 nodes ensuring best performance. As performance demands grow, more EC2 instances can be added to the cluster leveraging the autoscaling functionality. Conversely as performance demands shrink, the cluster can shrink back down by removing unwanted nodes. This model delivers on the cloud elasticity promise by ensuring that charges are only incurred for the precise resources, and only as long as they are required.
Scaling Capacity
Object storage has proven to be a highly cost effective storage platform for data lakes, but it struggles to meet the performance requirements of modern applications such as LLMs and AI training. However, by coupling the performance tier described with cost-effective object storage, it is possible to scale-up and scale-down capacity as demanded by applications. Utilizing intelligent data movement techniques between the two layers, optimal performance can be delivered with optimal and cost effective capacity scaling. Presenting a unified layer of communication protocols (POSIX, NFS, SMB and S3) multiple applications can access the same data set eliminating the need for multi-copies of the exact same data.
Build A True Storage Autoscaling Architecture
The WEKA Data Platform was designed from the ground up to leverage native cloud resources and deliver a dynamic infrastructure that can be precisely tuned to the performance and capacity requirements of the most demanding applications at less cost than cloud-native storage resources.
The following diagram provides an overview of a WEKA Data Platform deployment in the AWS cloud infrastructure. Although it should be noted that this is not limited to AWS alone, and can be deployed in Microsoft Azure, Google Cloud in a similar manner.
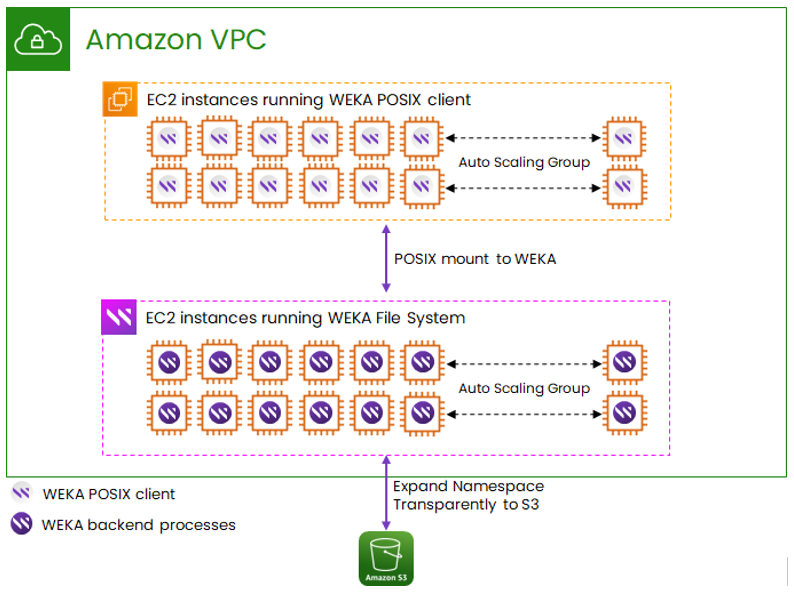
WEKA is deployed in a customer Virtual Private Cloud (VPC) leveraging the I3 EC2 instances which have local NVMe storage attached. A minimum of 6 instances is required to form the storage cluster and this can scale to tens or hundreds of instances leveraging the autoscaling functionality. The WEKA POSIX client is installed in the application nodes allowing multi-protocol communication to the WEKA cluster, supporting a wide variety of applications. The cluster can be thin-provisioned to support up to 1024 individual file systems, while the autoscaling feature ensures sufficient capacity to the cluster. Users can control the number of instances by either changing the desired capacity of instances from the AWS auto-scaling group console, or defining custom metrics and scaling policy in AWS. Once the desired capacity has changed, WEKA takes care of safely scaling up and down the instances. Internally and transparent to the application nodes, WEKA can attach an S3 bucket per file system for additional, low cost capacity expansion. This level of granularity ensures that performance critical applications can stay on NVMe only, while less demanding performance applications can enjoy optimal cost.
It’s easy to take advantage of WEKA autoscaling for your performance-intensive workloads in the cloud. By leveraging Terraform automation for AWS, Azure, and Google WEKA enables you to take a programmatic approach to your data to provision cloud resources and scale-up and down the environment.
In summary, the WEKA Data Platform delivers on the promise of cloud computing elasticity by tightly integrating the very popular autoscaling function, ensuring optimal performance, capacity and cost for demanding cloud applications. You can click on the following link to learn how 23andMe simplified their journey to the cloud and leveraged WEKA features like autoscaling, to minimize their cloud costs.
Popular Blogs From Barbara Murphy



Related Assets
-
Don’t Let the I/O Blender Destroy Your AI Model Training

Don’t Let the I/O Blender Destroy Your AI Model Training
-
Supercharging GPU Cloud for AI Workloads

Supercharging GPU Cloud for AI Workloads
-
How To Tackle Business and Technical Challenges Impacting Data-Intensive AI Workloads

How To Tackle Business and Technical Challenges Impacting Data-Intensive AI Workloads