Get More Out of AWS Custom Silicon

The AWS Nitro System is redefining how we build infrastructure in the cloud. The security, performance, scale, and time to market improvements are pretty well documented. With both Google and Azure now incorporating their take on the principles behind Nitro, this will be the default way to build infrastructure as we advance.
But the beginnings were fairly modest. In 2013, AWS quietly introduced their 3rd generation of compute-optimized instances in Amazon EC2 C3. Buried deep in the announcement blog post from Jeff Barr is a very innocuous line: “If you launch C3 instances inside of a Virtual Private Cloud and you use an HVM AMI with the proper driver installed, you will also get the benefit of EC2’s new enhanced networking. You will see significantly higher performance (in terms of packets per second), much lower latency, and lower jitter.” That enhanced networking was the very first network offload card. It represented the first time AWS had introduced an instance type that featured its own internally developed custom silicon for customers in what has become known commonly today as the AWS Nitro System.
Over the next ten-plus years, the concepts behind the Nitro System have driven a revolution in cloud computing and has become what James Hamilton refers to as the “unsung hero” of Amazon EC2. While AWS mainly touts the improvements in performance, security, and costs that EC2 customers get as a result of Nitro, the real impact from Nitro is only now being felt – resource densification. As an example, let’s compare the latest GPU-accelerated instances available from AWS in Amazon P5 versus Amazon P4d instances (Table 1 reproduced here from the P5 launch blog). In addition to 8 NVIDIA H100 GPU cards, the new P5 instances offer 2x the vCPU, 2x system memory, 8x network throughput, and nearly 4x the amount of local NVMe storage available per instance versus the previous P4d instances.
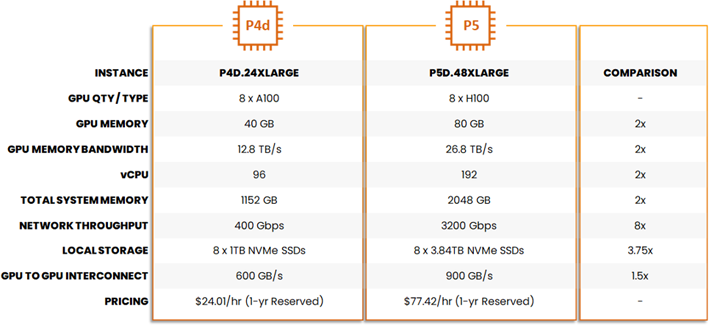
Table 1: Resource Densification in the Cloud
The Implications of Compute Densification for Your Data
This massive densification of resources is leading to a lot of goodness for customers in terms of performance – up to 20 exaflops of compute capacity according to AWS. This is an ideal environment for LLM model training and tuning, natural language processing, building neural networks, and most other AI applications. Without this level of resource density, the kind of AI and HPC development now happening in the cloud would not be possible. However, this level of compute densification is also coming at a cost to many customers in the form of low utilization.
As we pointed out in an earlier post, most customer scenarios involving AI today are suffering from an “IO blender effect” that results in suboptimal storage performance that slows down the AI training pipeline. In a nutshell, if the storage system is not designed for massive parallelization of both metadata and data operations, then it winds up serializing access, resulting in delays in responding to requests from clients. Further, if the storage system has been tuned for an individual workload profile (very much the norm today), then the mixed IO resulting from multiple overlapping AI training pipelines results in a blurring effect that increases latency and slows storage IO.
The sad reality is that traditional cloud data systems have become the bottleneck for many customers’ AI initiatives today. These systems weren’t built with AI workloads in mind. So they don’t provide the low latency needed to process thousands of metadata look-ups per second, enable massive bandwidth for ingesting data sets for training, or the high IO across a mixed file type profile required for typical model training and tuning scenarios. As a result, the massive performance available in the latest compute infrastructure sits idle, starved for data. In a twist of irony, some of the most valuable and scarce compute resources – GPU-accelerated servers – are impacted by this situation the most, and it’s costing customers millions.
A Better Way: Converged Architecture
The massive density in compute infrastructure itself offers a way forward through the data bottleneck – converged infrastructure. It’s not a new term. In fact, WEKA has been offering converged storage solutions for some time now. But in the cloud, a converged approach can lead to a big jump forward in resource utilization, promising to save customers without impacting performance. It works just how it sounds. You run the data platform on the same cloud compute resources – the same compute instances, the same network interfaces – that support your application.
It helps to compare a traditional (or dedicated) storage environment with a converged to make things clear (see Figure 1). Here we’re contrasting the approach provided by WEKA on AWS in both dedicated and Axon. In the dedicated mode, the WEKA software runs on a cluster of dedicated of EC2 instances in its own VPC. The WEKA cluster uses a storage protocol (like POSIX, S3, or NFS) to connect to the customer applications, which run in a totally separate VPC. In Axon, there is only one cluster of EC2 instances in a single VPC. The WEKA software and the applications share the EC2 instances.
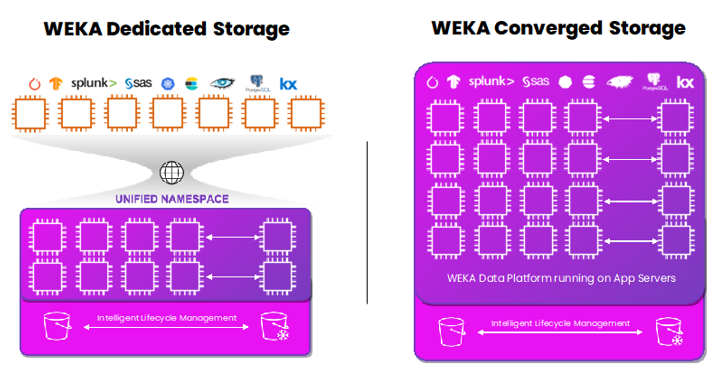
Figure 1: WEKA Dedicated versus NeuralMesh Axon in AWS
How it Works: NeuralMesh Axon for AWS
We can create a new WEKA cluster using the customers’ production instances. To run data operations, a customer might use 8 or 10 total instances in the WEKA cluster. Usually, with 8 instances, a customer can drive over 1 million IOPs and achieve sub-millisecond latency in AWS, so it’s very fast with even a small environment. This approach is most valuable for customers training and tuning AI models or building new HPC applications in AWS, so typically, the customer environment includes hundreds or even thousands of EC2 instances. For the moment, NeuralMesh Axon in AWS is supported for P4d and P5 instances in AWS as these have the combination of high-density compute along with high-performance local NVMe flash available.
The key to making Axon work is in managing resource allocation at the instance level. Table 2 below provides an example summary of how resources would be allocated in NeuralMesh Axon using P4d instances. We assign to NeuralMesh 6 vCPUs out of 92 total available, 7 ENIs, and about 24 GB of memory. We don’t use any of the GPUs, WEKA doesn’t need those, and you want those available for training and inference anyway. Then WEKA takes most of the NVMe flash memory available in the instances to drive high-performance storage.
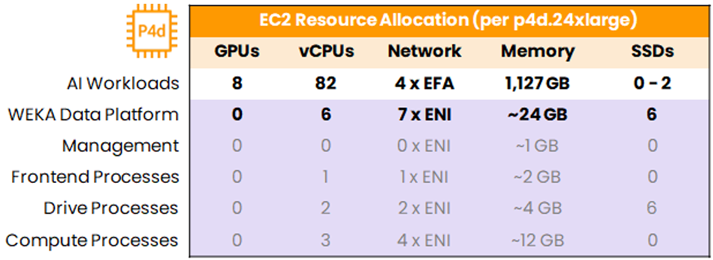
Table 2: EC2 Instance Resource Allocation for NeuralMesh Axon in AWS
So… is Axon in the Cloud for Me?
Selecting between dedicated and Axon is a tradeoff between cost optimization and operational complexity. Since applications and data share the same resources, each needs to know what resources are available with no surprises. The application and the storage should have different resiliency models and different failure domains. Each side needs to know what resources to expect available to them at any given time. So we bring in a job scheduler tool like SLURM and resource orchestration tools to handle resource allocation. Also, the application and the data need to be good citizens when sharing resources. You don’t want the application to have direct access to instances supporting the storage platform in a way that impacts data operations. So the deployment needs to ensure you restrict root access and that you have good change control policies in place.
For that added complexity, the cost benefits of running your NeuralMesh in Axon in AWS are massive. Think about the annual cost of 100 TB of Lustre storage in the cloud – about $700k per year[1]. For the moment, we’ll leave aside the amount you might spend on resource over-provisioning Lustre to drive millions of IOPs, hundreds of GBps of bandwidth and storage that supports the millisecond latency required for AI applications today. Now contrast that with the idea that, in NeuralMesh Axon on AWS, there is no infrastructure to buy – at all. Remember in Axon, the WEKA software is running on infrastructure you’ve already deployed for your applications. So to support high-performance data operations in converged, you pay for the WEKA Software licenses, and that’s it. So for comparison, the WEKA list price for is $100k per year for 100 TB of data (assuming 100% flash storage), and that’s it. With early customers who are adopting this approach, we’ve found the cost savings scale massively.
To see if running WEKA in Axon is right for you, Get In Touch
[1] All prices are based on listing prices as of March 2024. See AWS Marketplace listing for WEKA here: https://aws.amazon.com/marketplace/pp/prodview-2mfqnh6p4yurs See Amazon FSx-Lustre pricing here: https://aws.amazon.com/fsx/lustre/pricing/
Popular Blogs From Phil Curran



Related Assets
-
The NAND Flash Shortage Survival Guide

The NAND Flash Shortage Survival Guide
-
See NeuralMesh in Action

See NeuralMesh in Action
-
The Buyer’s Guide to AI Storage

The Buyer’s Guide to AI Storage