Accelerate Distributed Model Training with WEKA Support for Amazon SageMaker HyperPod

Distributed model training and development requires a data platform that is massively scalable and highly performant. As training datasets grow exponentially, the sheer volume of data can overwhelm traditional data pipelines. Performance limitations in the underlying storage architecture add weeks or months to epoch times, delaying time to market. Developers attempt to implement pre-fetching or data caching strategies that add unnecessary costs and waste developer time on manual data management. Long model checkpoint times that result from underpowered data architectures further delay training runs and can impact the resilience of the infrastructure. Finally, insufficient performance in the underlying data environment causes the GPU/compute cluster to go underutilized, delaying model training and adding to overall GPU infrastructure costs.
To address these challenges, we’re pleased to announce WEKA support for Amazon SageMaker HyperPod, enabling organizations to accelerate distributed model training, increase GPU utilization, and improve developer productivity. The computational environments required to build, train, and run foundation models for generative AI continue to increase exponentially to meet the needs of large-scale distributed training. AWS introduced Amazon SageMaker HyperPod at AWS reInvent 2023 to help increase training cluster resilience and reduce the time to train foundation models. By providing a purpose-built infrastructure with self-healing capabilities that automatically detect hardware failures and replace faulty instances, HyperPod customers can dramatically improve cluster resilience, which in turn helps accelerate model training times and reduces overall model training costs.
With WEKA support for Amazon SageMaker HyperPod, customers can build a high-performance data platform for AI model development that scales massively, increases GPU infrastructure utilization, and reduces infrastructure costs. The zero-copy, zero-tuning architecture WEKA provides delivers high-performance data for every phase of the FM model training across data loading, pre-processing, model training, checkpointing, verification, tuning, and data set archiving. With WEKA, organizations are able to reduce model checkpoint times by 90%, enabling faster training times and increasing the resilience of customers’ SageMaker HyperPod deployment. WEKA software also enables customers to reduce model data load times by 50%, accelerating model training times and improving research and development productivity. Customers using WEKA for SageMaker HyperPod experience 5x faster storage performance for their overall model training initiatives, which helps reduce model training epochs from months to days. With faster overall storage performance, customers using WEKA for the SageMaker HyperPod environments are able to fully saturate the cluster, driving GPU utilization to over 90%. This level of infrastructure utilization enables customers to optimize their cloud infrastructure use and get more from their investment in GPU-accelerate infrastructure on AWS.
How Stability AI Accelerated Model Training with WEKA for SageMaker HyperPod
Stability AI is a leading open-source generative AI company, building foundation models with tens of billions of parameters, which require the infrastructure to scale training performance optimally. Stability AI is an early user of SageMaker HyperPod and WEKA customer. With WEKA, most AI training data is retained in low-cost object storage on Amazon S3 while automatically tiering data up into the high-performance NVMe flash tier as needed to complete a model training run—all without intervention by researchers, infrastructure, or MLOps teams. With these capabilities, Stability AI has seen model training times accelerate by 35%, GPU utilization to increase from 30-35% prior to WEKA to above 90%, and increased developer productivity with simplified data operations. Using WEKA, Stability AI has transformed its infrastructure strategy on AWS, driving increased resource utilization, while increasing model training speeds, enabling them to get more from their SageMaker HyperPod investment and accelerate time to market for new models and new capabilities.
“In AI model training, you have petabytes of data moved for every training run. With WEKA for SageMaker HyperPod, we’re able to get maximum use of the GPU and memory resources in the cluster by eliminating data bottlenecks,” according to Chad Wood, HPC Engineer at Stability AI. “The step-function improvements in data performance have helped us build a more resilient training environment that enables us to build state of the art models faster.”
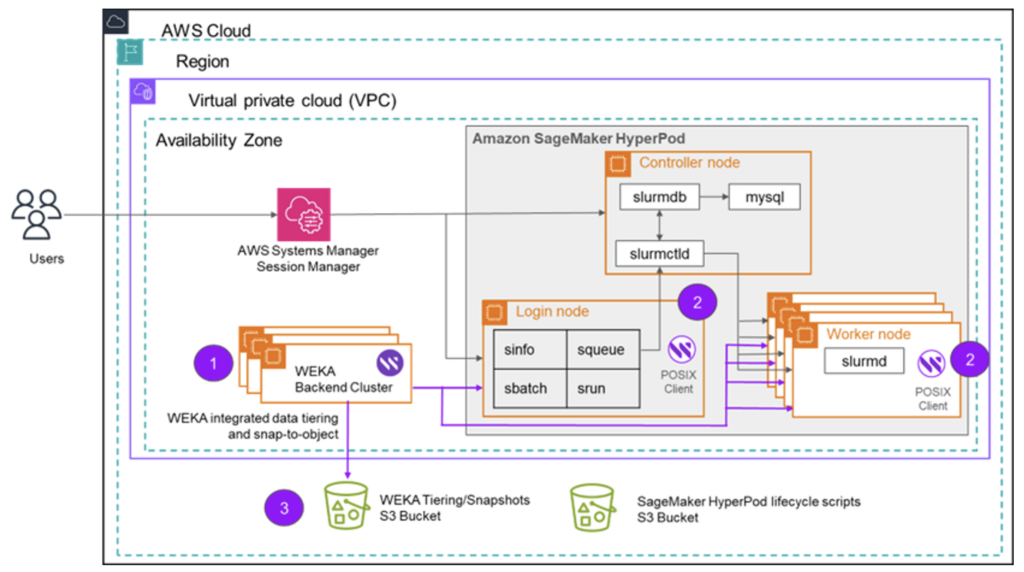
WEKA for SageMaker HyperPod Overview
To get started with WEKA for SageMaker HyperPod, customers can create their SageMaker HyperPod cluster in slurm orchestration mode using guidance provided by AWS here. Slurm is a popular open-source cluster resource management system used widely by high performance computing (HPC) and generative AI and FM training workloads.
Once your SageMaker HyperPod cluster is configured in your VPC, you’ll simply deploy WEKA to that VPC. WEKA software deploys to EC2 i3en instances with local flash storage to form a high-performance storage layer. The single namespace from WEKA extends to an S3 bucket for high-capacity storage at the lowest cost. The WEKA client deploys to SageMaker HyperPod nodes to ensure the highest storage IO and lowest latency.
To learn more about WEKA for Amazon SageMaker HyperPod, you can visit our WEKA for AWS detail page. To get started with your WEKA for SageMaker HyperPod and other high-performance workloads in AWS, get in touch with us to arrange a demo.
Arrange a Demo
Popular Blogs From Phil Curran



Related Assets
-
The Impact of Storage on the AI Lifecycle

The Impact of Storage on the AI Lifecycle
-
See NeuralMesh in Action

See NeuralMesh in Action
-
Scaling Smart: Future-Proofing Your AI Infrastructure

Scaling Smart: Future-Proofing Your AI Infrastructure