WEKA’s Augmented Memory Grid—Pioneering a Token Warehouse for the Future

In the era of AI factories, tokens have become the fundamental data currency—pushing the boundaries of what’s possible with agentics, robotics, and reasoning. Every interaction—whether a prompt, a response, or an autonomous action—gets translated into tokens. As AI inference continues to grow at a staggering pace, the challenge isn’t just handling massive amounts of tokens, it’s managing them cost-efficiently and at scale.
Traditional large-scale inference pipelines waste valuable cycles by repeatedly translating, or recomputing, tokens on the GPUs—the AI equivalent of invoking your most expensive translator for every request. This approach to caching and memory does not scale and inevitably burns through the GPU memory, hitting a wall. Solving for this memory barrier leads to inflated time-to-first-token (TTFT), wasted floating-point operations per second (FLOPS), and increased total cost of ownership (TCO).
WEKA’s Augmented Memory Grid™ capability flips that system on its head and extends GPU memory to a token warehouse™ in NeuralMesh to provide petabytes of persistent storage at near-memory speed. This token warehouse, powered by Augmented Memory Grid, is a breakthrough approach to caching and memory constraints.
Trillions of Tokens Reshape the Tokenomics of AI
As agentic AI and robotic swarms come online in 2025, token generation will explode exponentially, with projections expecting up to 86,400 trillion tokens per day. Agents and robots will do most of the work, and their output tokens and actions will be how that work is measured and valued. As AI models continue to grow larger and more complex to support this next wave of AI, the ability to store, retrieve, and reuse tokens efficiently is critical to unlocking performance, reducing costs, and driving inference profitability.
This shift will fundamentally reshape token economics: efficiency, speed, and cost per token will become the defining metrics of success. To compete, AI factories must be rearchitected not just for raw power but for token-level performance and reuse—and that’s exactly what WEKA’s Augmented Memory Grid and token warehouse capabilities are built for.
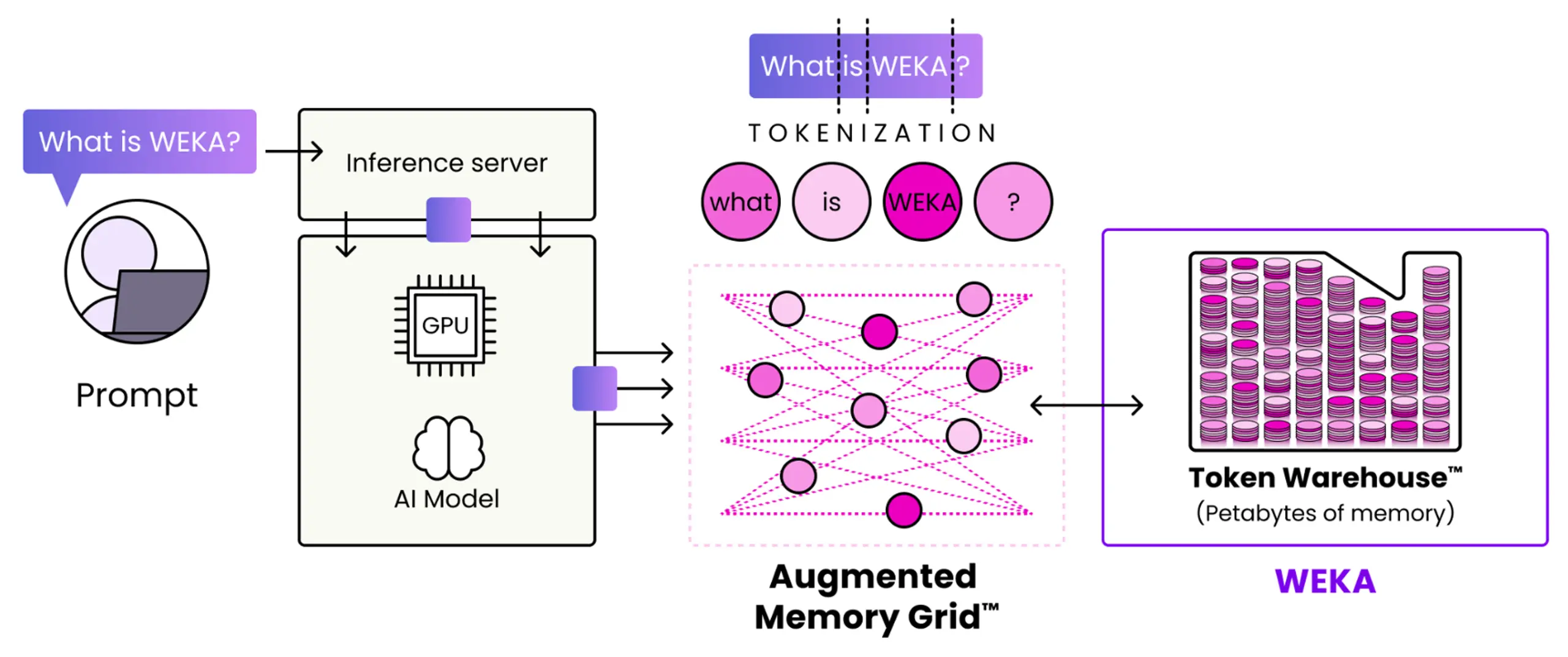
The token warehouse provides a persistent, NVMe-backed store for tokenized data, allowing AI systems to store tokens and retrieve them at near-memory speed. The goal: to translate once, persist indefinitely, and serve at memory-tier speed. This powerhouse enables you to cache tokens and deliver them to your GPUs at microsecond latencies, driving the massive-scale, low-latency inference and efficient reuse of compute necessary for the next generation of AI factories.
An Online Retailer’s Fulfillment Center, but for AI
WEKA’s token warehouse, powered by Augmented Memory Grid, fixes the memory inefficiency by:
- Persistently storing tokenized data in NVMe, resulting in a more affordable, scalable, and lower-power solution.
- Serving tokens at near-memory latency, without redundant retranslation.
- Extending GPU memory with a high-performance, distributed data fabric.
Instead of treating tokenized data as transient compute artifacts, the token warehouse turns them into durable, retrievable assets. Think of it as a fulfillment center: tokens are stored, and pulled “off the shelf” at inference time, instead of continuously being re-manufactured on-demand for every single request.
Just like a fulfillment center stores millions of products and delivers them instantly when ordered—without needing to recreate or reorder each item every time—NeuralMesh with Augmented Memory Grid provides a token warehouse capable of persistently storing billions of tokens and making them immediately available to GPUs during inference.
Instead of recomputing token embeddings from scratch (like remanufacturing a product every time someone buys it), the warehouse allows AI models to "pull from the shelf" in real-time, drastically reducing latency, increasing utilization of compute resources, reducing associated energy consumption, and accelerating performance at scale.
WEKA’s Augmented Memory Grid fuels token warehouses by bridging the performance gap between GPU memory and traditional storage. It extends GPU memory into a distributed, high-performance memory fabric that delivers microsecond latency and massive parallel I/O—critical for storing and retrieving tokens at scale in real-time.
Building a token warehouse isn’t possible with legacy storage solutions, which simply can't overcome the latency barrier to deliver the required throughput and scale needed for real-time token retrieval. With WEKA’s Augmented Memory Grid and the token warehouse, it’s not just faster storage—it’s a new tier of memory that redefines how inference systems access and reuse data.
The Unique Architecture of NeuralMesh Powers the Token Warehouse
NeuralMesh was purpose-built to deliver a unique, antifragile architecture that delivers exceptional performance and economics at scale, providing a comprehensive token management solution for AI model providers, GPU clouds–or AI clouds–and enterprises. NeuralMesh’s architectural differentiators include:
- Direct Access to the GPU: By leveraging GPU Direct Storage and RDMA, Augmented Memory Grid lets GPUs fetch tokens directly at microsecond latencies. There is nothing else between the token warehouse and a GPU.
- GPUs and NeuralMesh Think Alike: NeuralMesh software provides a high-performance distributed parallel file system to manage large sequential reads and small random accesses. Because it scales this way, it aligns with how GPUs work—matching their parallelism and demand.
- NeuralMesh Is Built for NVMe: Because NeuralMesh is optimized for NVMe, it can easily take small amounts of data and shred them into 4K chunks. Imagine your inference model just tokenized a phrase and read it. NeuralMesh will then parse it into 4K blocks and spread it out across the fastest disks available in the system, helping you maintain consistent performance as your inference workload grows.
- Infinite Training and Inference Systems: WEKA Augmented Memory Grid ensures you can access rich inference data stored in your token warehouse and use it to train AI models as well—without having to copy tokens.
NeuralMesh’s innovative architecture is accelerating the next frontier of AI economics—or ‘tokenomics’—offering a cost-effective solution for scaling AI applications without compromising performance, throughput, or accuracy.
AI Efficiency Is No Longer a Tradeoff, it's Essential
Organizations that can operate ultra-efficient token warehouses to feed swarms of AI agents and robots in near-real time will ultimately win the race to industrialize AI. Leveraging capabilities like WEKA’s Augmented Memory Grid, which are engineered to accelerate token production and lower your cost per token offers a significant competitive advantage to help you win.
What's Next



Scale Production AI Faster with NeuralMesh
Your models aren't slow. Your data is. Fix AI bottlenecks with high-throughput infrastructure.