Ultra Fast Data Platform That’s Redefining Performance Efficiency

In the world of artificial intelligence and high-performance computing, one thing is clear—speed is the key to unlocking AI’s potential. As companies generate tremendous amounts of data, the need to access, analyze, and store that data in real-time becomes crucial, especially in data-intensive industries like finance, healthcare, and media where latency can severely impact decision-making and outcomes. AI models depend on rapid, uninterrupted access to massive datasets, and system bottlenecks can be catastrophic.
That’s where WEKA comes in.
At WEKA, we deliver a data platform that not only offers lightning-fast performance but does so with exceptional efficiency, maximizing both space and power utilization. Our platform is purpose-built to handle the massive data requirements of AI workloads, empowering companies to accelerate their pipelines and eliminate bottlenecks. For those accustomed to the limitations of legacy technologies, our performance can seem almost unbelievable—until they experience it firsthand.
WEKA is fast, exceptionally fast. It’s no surprise that many new users ask the same question: “How can you deliver orders of magnitude better performance while maintaining such efficiency?” The answer lies in WEKA’s innovative architecture, designed for the future of AI and high-performance computing.
The secret? It’s not just one thing. WEKA’s performance isn’t the result of a single innovation or feature; it’s a combination of multiple, cutting-edge technologies working together seamlessly to deliver an unparalleled experience. Below, we’ll dive deep into the technological underpinnings that make WEKA so fast and why it’s reshaping the way enterprises think about data storage and management.
Distributed Metadata Management and Virtual Metadata Servers
One of the key reasons behind WEKA’s incredible speed is its distributed metadata management system. Unlike traditional systems that rely on a single metadata server or centralized databases, WEKA takes a different approach that scales out horizontally without bottlenecks.
When people talk about metadata, they’re referring to the data about your data—information that helps systems know where a file is located, how it’s structured, who can access it, and how it should be handled. In traditional systems, metadata often becomes a performance choke point, limiting scalability and creating “hotspots” where too much traffic hits a single metadata server.
WEKA eliminates these issues with its innovative virtual metadata servers. The system doesn’t rely on just one or a few metadata servers. Instead, it runs multiple virtual metadata services across all the nodes in a cluster. Each metadata server only handles a small portion of the total namespace, so the workload is automatically distributed.
Here’s where it gets really clever: the metadata plane is sharded into thousands of small “buckets,” with each virtual metadata server responsible for only a subset of the namespace. As clients access different files, they interact with different metadata servers. Even if multiple clients access the same file but in different block ranges, the load is split across different virtual metadata servers. This means no single metadata server becomes a bottleneck and the virtual metadata servers do not interact with each other, therefore, there is no wasted east-west communication that degrades performance as you scale more servers
Each 8 MB chunk of a file is handled by a different virtual metadata server, which results in a significant distribution of workload across the entire system. The load-balancing mechanism further ensures that no “hot spots” form, preventing performance degradation and maintaining the efficiency of the entire platform.
Additionally, WEKA’s metadata servers are resilient. They journal to the underlying distributed and protected storage to ensure consistency and fault tolerance. This level of redundancy ensures that your data remains accessible even if a failure occurs. Another crucial aspect of WEKA’s metadata management is that it is entirely calculation-based, meaning that it eliminates the need for memory-based lookup tables, reducing overhead and boosting overall performance.
Kernel Bypass for Low Latency: Eliminating Bottlenecks in the I/O Path
Latency is the bane of high-performance computing, and in traditional systems, the kernel stack is often a significant source of delay. Context switches and kernel calls add overhead, which can slow down data processing. WEKA bypasses these traditional bottlenecks through a process known as kernel bypass.
By utilizing the Data Plane Development Kit (DPDK), WEKA maps network devices directly into user space, bypassing the kernel entirely. This allows network operations to proceed without the usual overhead associated with kernel resource consumption. In simple terms, data can travel from point A to point B much faster because it’s no longer being bogged down by unnecessary kernel interactions.
Kernel bypass applies to both backend and client hosts, which means the WEKA system can fully saturate high-bandwidth connections like 200Gb or 400Gb Ethernet or InfiniBand links. This enables the platform to achieve the kind of performance that would be impossible with traditional systems – massive performance for a single client as well as massive performance per storage node across all dimensions of performance – throughput, IOPs, and low latency, even under heavy workloads.
WEKA also achieves high-speed data access by utilizing the Storage Performance Development Kit (SPDK) to bypass the operating system’s kernel when communicating with NVMe devices. Traditional storage systems rely on the kernel, which adds overhead through context switches and interrupts, slowing down data operations. By bypassing the kernel again, WEKA minimizes this overhead, enabling faster direct communication between the storage software and the NVMe devices.
SPDK’s polling mechanism further enhances performance by eliminating the delays caused by interrupts. Instead of waiting for IO completions, the system continuously polls for them, reducing latency and enabling much faster IO operations. This is particularly beneficial for high-performance applications like artificial intelligence, machine learning, and real-time analytics, where minimizing delays in data access is critical.
In addition to lower latency, SPDK’s kernel bypass approach allows WEKA to maximize throughput by optimizing CPU utilization. The system is able to handle millions of IO operations per second (IOPS) and efficiently scale across multiple nodes, which is essential for handling large-scale, data-intensive workloads.
The ability to bypass the kernel to access the network and NVMe devices also brings another key benefit: scalability. Because the kernel stack is bypassed, WEKA can scale horizontally across multiple hosts without the performance degradation that usually accompanies such scaling efforts. This allows for linear performance gains as more resources are added, which means enterprises can scale their infrastructure without worrying about hitting bottlenecks.
4K Granularity: Aligning Perfectly with NVMe for Maximum Performance
Another crucial factor in WEKA’s unmatched speed is its ability to write to the filesystem with 4K granularity. For those unfamiliar, NVMe (Non-Volatile Memory Express) storage is the new gold standard for high-performance storage solutions. NVMe devices are optimized for flash storage and can deliver staggering amounts of IOPS (Input/Output Operations Per Second) and bandwidth.
However, in many traditional systems, the full potential of NVMe isn’t realized due to inefficient data writing techniques. Traditional systems might write data in chunks that don’t align well with NVMe’s 4K sector size, resulting in wasted performance potential.
WEKA solves this problem by aligning its data writes precisely to NVMe’s 4K sectors. This allows the platform to handle all IO patterns—whether the IO size is small, large, or a mixture of both—with incredibly low latency. And because WEKA’s data layout algorithms are designed to parallelize both metadata and data across the cluster, the performance benefits scale out with the system.
Whether your workload involves small files, large files, or a mix, WEKA can handle it with ease. There’s no need to spend time tuning for specific IO patterns because WEKA is designed to adapt dynamically to the workload in real-time.
The Efficiency Side of Speed: Space and Power Optimization
Speed is only one side of the coin. In today’s world, where sustainability and resource efficiency are just as important as raw performance, WEKA is designed to deliver both speed and efficiency. Traditional storage solutions often suffer from inefficiencies in both space utilization and power consumption, but WEKA stands out in both categories.
In traditional architectures, as systems scale, the need for more space and power grows exponentially. But WEKA’s innovative data architecture ensures that its scaling is not only linear in terms of performance but also efficient in terms of resources. WEKA’s software-defined architecture, coupled with its 4K granularity and virtual metadata servers, ensures that no resource is wasted—whether that resource is storage capacity or electrical power.
Moreover, because WEKA is software-defined, the exact same technology can be used both on-premises and in the cloud. This allows enterprises to take full advantage of cloud scalability and efficiency without sacrificing performance or dealing with different architectures for on-premises and cloud environments.
With WEKA, organizations can reduce their data center footprint, lower their power consumption, and optimize their resource usage—all while achieving industry-leading performance. This combination of speed and efficiency is why WEKA is trusted by some of the most data-intensive industries in the world, including financial services, genomics, AI/ML, and media and entertainment.
The Hidden Costs of Competitors’ Larger Systems
Competitors that lack WEKA’s performance efficiency often need to compensate by deploying larger, more resource-intensive systems to match similar performance levels. These larger systems require more physical infrastructure, consuming significantly more data center space. As AI models demand rapid access to massive datasets, these competitors struggle to keep pace, needing additional hardware to handle the increased load. This creates not only a spatial challenge but also a substantial increase in operational complexity and costs, as they need to manage and maintain a larger number of servers and storage devices.
Larger systems require significantly more cabling to connect the additional servers, storage devices, and networking components, leading to increased complexity in the data center. One competitor uses 6 times more cabling than WEKA. More cabling not only takes up valuable space but also adds to the physical clutter, making maintenance and troubleshooting more difficult. This increased cable density can also obstruct airflow, causing systems to overheat, which in turn requires even more energy for cooling. Additionally, the cost of cabling, switching, and managing the network infrastructure rises with the need for more hardware, further driving up operational expenses.
The energy inefficiencies in traditional systems further exacerbate the problem. Competitors without WEKA’s power optimization technology are forced to scale horizontally, which leads to higher energy consumption. Each additional system in the infrastructure draws more power, and the inefficiency multiplies with each unit added. This can be especially problematic in industries that prioritize sustainability and are looking for ways to reduce their carbon footprint. The larger systems also require additional cooling, increasing the energy demand even further.
Moreover, competitors often face diminishing returns in performance despite the larger setups. Traditional architectures are unable to scale as efficiently as WEKA, leading to bottlenecks in data flow and processing. As these systems grow, the need for east-west communication between servers and the inefficiency in metadata handling leads to slower performance and higher latency. This contrasts sharply with WEKA’s streamlined architecture, which is purpose-built to handle these workloads efficiently, allowing it to maintain top-tier performance without the need for excessive power and space.
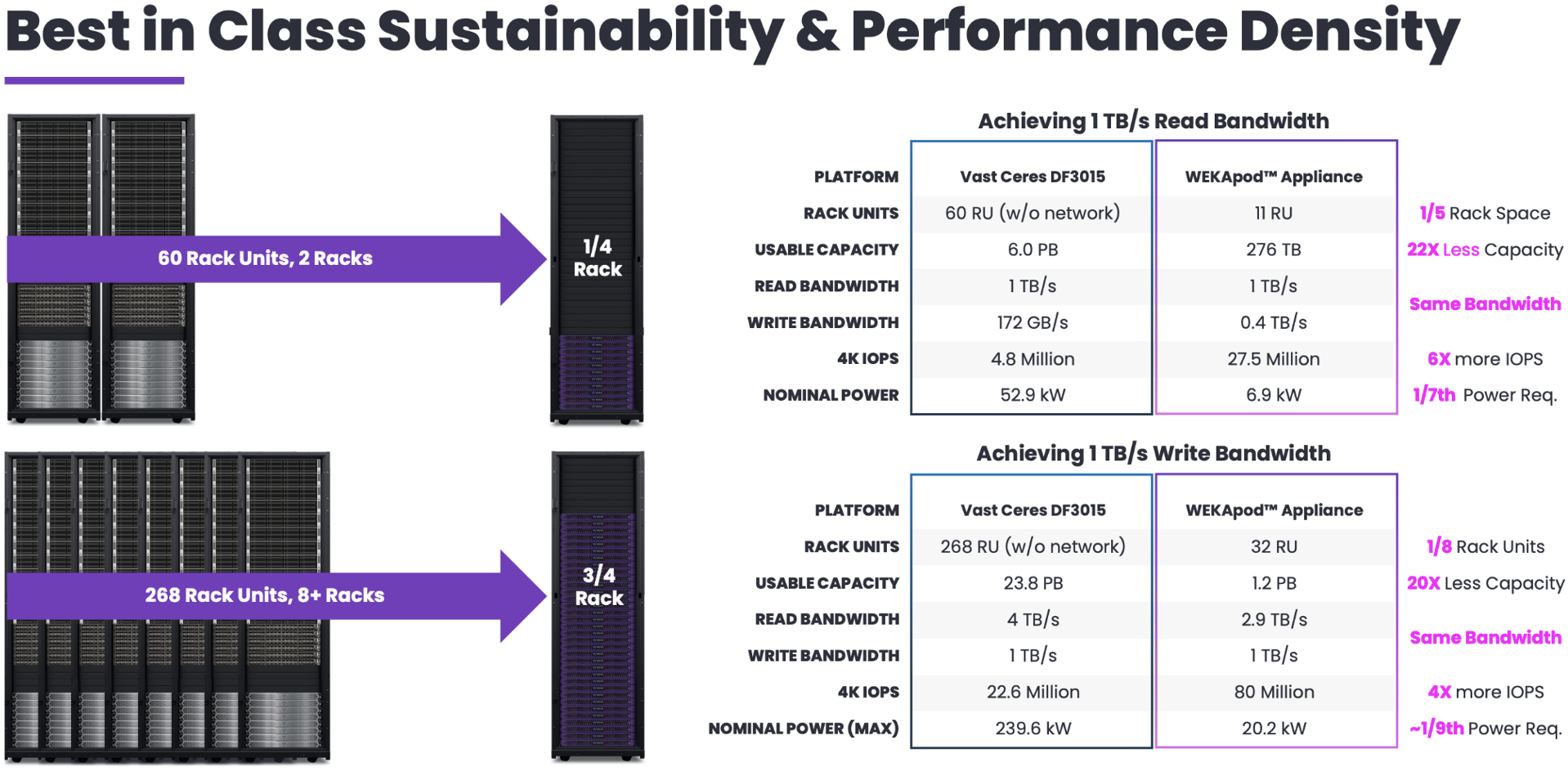
WEKA’s performance density, optimized for specific use cases, allows customers to significantly reduce the amount of storage, networking, GPU, and server resources needed. By improving GPU efficiency, WEKA ensures that tasks like training and inference run at peak performance, reducing idle time and energy consumption. This efficient use of resources and minimized data movement leads to lower energy costs and a reduced carbon footprint, helping meet sustainability goals while advancing AI innovation.
For example, WEKA delivers 1TB/s of read bandwidth with fewer than half a rack, compared to legacy solutions requiring two full racks, and uses just one-sixth the power. On the write side, WEKA outperforms competitors by providing 1TB/s of write bandwidth with a single rack, versus 9 racks from others, delivering nearly three times the IOPS while consuming only one-ninth the power.
A Breakthrough in Innovation
WEKA’s incredible speed is the result of multiple, cutting-edge innovations working in harmony. From distributed metadata management and virtual metadata servers to kernel bypass and 4K granularity in data writing, every aspect of WEKA’s architecture is designed to eliminate bottlenecks and deliver performance that is simply unmatched by traditional systems.
But what makes WEKA truly stand out is its efficiency. In an era where businesses are increasingly concerned about sustainability and resource optimization, WEKA proves that you don’t have to sacrifice performance to achieve efficiency. With WEKA, you can have both.
For organizations dealing with large volumes of data, the choice is clear: WEKA offers a future-proof solution that delivers the kind of speed, efficiency, and scalability needed to stay ahead in today’s data-driven world.
Popular Blogs From Colin Gallagher



Related Assets
-
See NeuralMesh in Action

See NeuralMesh in Action
-
Practical Strategies for Navigating the Memory Shortage

Practical Strategies for Navigating the Memory Shortage
-
Breaking Down the Memory Wall in AI Infrastructure

Breaking Down the Memory Wall in AI Infrastructure