New Augmented Memory Grid Revolutionizes the Economics of AI Inference Infrastructure

In previous posts, we’ve highlighted how AI Tokenomics is at the forefront of our innovation and how it’s reshaping the entire industry—especially as we enter the era of agentic AI and the onset of even larger large language models (LLMs) as well as large reasoning models (LRMs) to support this next stage.
One particular focus for token efficiency is around optimizing memory for the inference system. Models supporting AI agents are delivering longer context windows and prompt responses that include PDFs, videos, and even entire code bases. This requires an increasingly expansive amount of memory, forcing model builders to make critical trade-offs to exceed their fixed amount of memory and avoid hitting a memory wall. These constraints severely limit the capabilities of AI applications, resulting in a loss in trust for end users due to slow prompt results and non-optimal usage of the GPUs and subsequent infrastructure.
Breaking the Memory Wall Barrier—Introducing WEKA Augmented Memory Grid
Today we’re announcing Augmented Memory Grid™️, a new capability that extends GPU memory to the WEKA®️ Data Platform to cache prefixes or key value (KV) pairs. WEKA Augmented Memory Grid provides large, persistent memory that integrates with the NVIDIA Triton Inference Server and enables AI model builders to overcome traditional memory limitations.
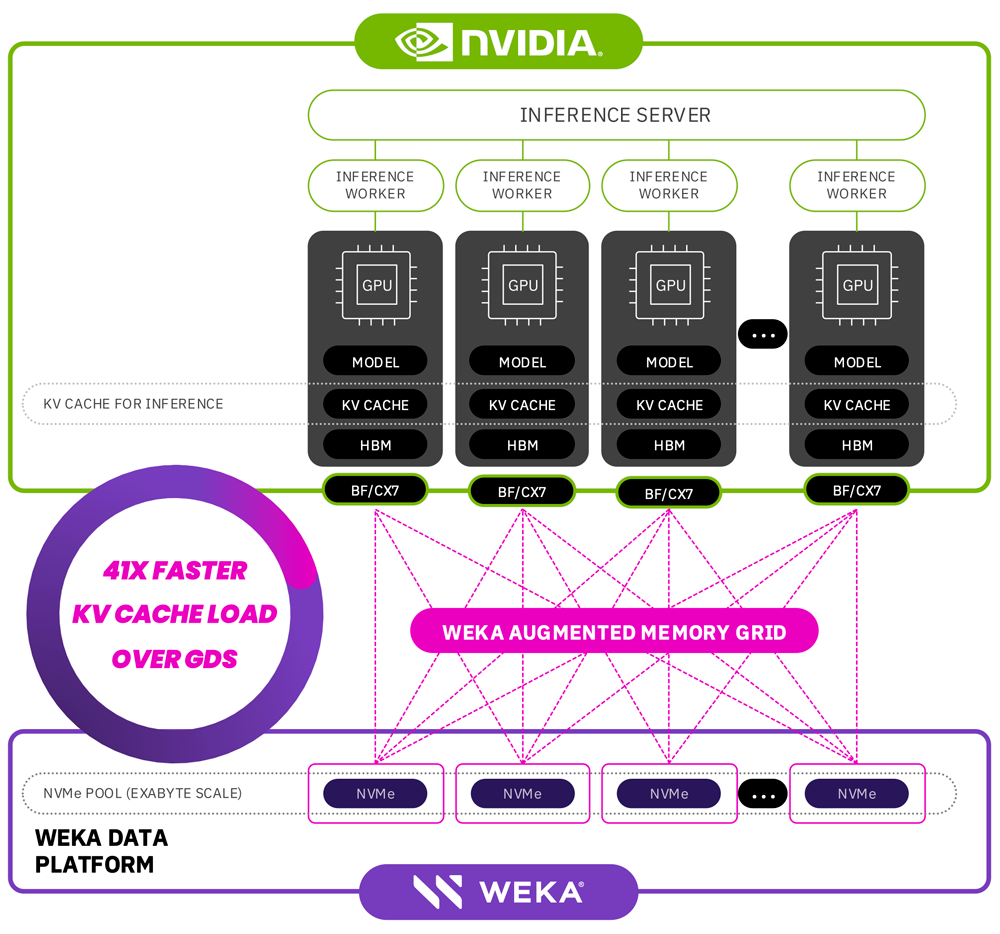
WEKA Augmented Memory Grid is uniquely architected to bring:
- Petabytes of Persistent Storage for KV Cache—For the very first time, the memory for large AI model inferencing extends to petabytes of memory—around three orders of magnitude or 1000x more than today’s fixed DRAM increments of single terabytes.
- Optimizations for Inference Infrastructure—The addition of persistent memory removes the need to over-provision GPUs when memory is full and the subsequent trade-offs between speed, accuracy, and cost.
- Dynamic Resource Reallocations—By offloading KV Cache data from HBM DRAM, GPUs can focus on the most critical tasks which improves performance across the inference system.
Agentic AI workloads, along with the focus on token efficiency for the inference system, require a new approach to AI infrastructure and data storage systems. WEKA’s Augmented Memory Grid capability, alongside the recently announced NVIDIA AI Data Platform brings the combined expertise of WEKA’s High-Performance Storage and NVIDIA-accelerated computing to optimize AI workloads for this new era.
The capabilities of Augmented Memory Grid will be made generally available soon.
Current Inference System Limitations
Today, cost effective inferencing is one of the toughest challenges in AI workloads. The modern inference system is very complex and requires multiple APIs, the ability to run different models, reasoning, purpose-built infrastructure, prompt and answer caching, and agentic workflows. This complexity directly impacts throughput and latency and, as a result, cost per token. These direct impacts are driven by GPU costs—which in turn directly affect profit margins. Today, significant engineering resources are being utilized to optimize token throughput and reduce time to first token latency for large language models.
One of the biggest challenges to date is working around memory wall barriers by minimizing redundant GPU token prefill. AI model providers are expanding their memory footprint with several tactics, including overprovisioning of GPUs, the most cost-intensive infrastructure resource.
With memory requirements continuing to expand due to growing model sizes, user demand, newer reasoning models, capacity constraints, performance trade-offs (such as offloading model weights to a slower and higher-capacity tier of memory like CPU DRAM), and KV Cache sizes, AI model builders are hitting the memory wall more often.
How Augmented Memory Grid Can Drive Significant Scale
WEKA’s Augmented Memory Grid’s capability is a revolutionary software-defined extension, which provides exascale cache at microsecond latencies with multi-terabyte-per-second bandwidth, providing near-memory speed performance at microsecond latencies necessary for today’s AI models. With an input sequence length of 105,000 tokens, Augmented Memory Grid in our lab resulted in a 41x reduction in time to first token (TTFT) prefill time, showing a significant gain for long context windows and dramatically changing the response time to an end user’s query from 23.97 seconds to just 0.58 seconds.
By using WEKA as large, persistent memory and freeing up the GPU memory, inferencing clusters can achieve higher cluster-wide throughput tokens, lowering the cost of token throughput by up to 24% for the entire inference system.
AI innovation is growing exponentially. The acceleration of agentic AI supported by the capabilities that reasoning models bring to the table, are continuing to drive innovation to its peak performance. As the economics of AI continue to evolve—infrastructure selection continues to be a decisive factor. Having AI infrastructure solutions alongside these systems that can reduce costs on token generation will continue to be a dominant theme in the economics of AI.
Learn more about WEKA and the evolving landscape of AI tokenomics
Related Assets
-
Designing a Strategy to Scale and Optimize Your GPUs

Designing a Strategy to Scale and Optimize Your GPUs
-
Supercharging GPU Cloud for AI Workloads

Supercharging GPU Cloud for AI Workloads
-
Checkmate on Checkpoints in LLM Development

Checkmate on Checkpoints in LLM Development