Fit for Purpose: GPU Utilization

GPU Utilization is a crucial metric – and maybe the metric – for AI because the GPUs that handle the parallel computations needed for tasks like deep learning and neural networks are often the most expensive components in a data center. Efficient GPUs means faster training and inferencing and more cost-effective AI implementations. Your storage system plays a crucial role in whether your GPUs are fully optimized and running at peak efficiency. To achieve this, a high-performance storage system must deliver data to the GPUs at the same rate they can process it, reducing GPU utilization bottlenecks that can slow down training or inference tasks. If the storage system can’t keep up, GPU utilization drops, leading to inefficiencies, longer processing times, and higher costs. Therefore, an optimized storage system ensures that data is delivered at a speed that allows GPUs to maintain maximum utilization, keeping AI workloads running smoothly and efficiently while balancing GPU utilization and cost.
Version 1.0 of the MLPerf® Storage benchmarks were released last week and WEKA is proud to once again showcase its outstanding performance in these benchmarks. In machine learning, particularly deep learning and AI workloads, storage can have an outsized impact on overall system performance. These workloads require handling massive datasets, with high data ingestion rates and frequent read/write operations during training, testing, and inference. The MLPerf Storage Benchmarks are designed to evaluate how well storage systems manage these intensive data demands and they showed how fit for purpose data platforms best address the performance and utilization needs of AI data pipelines.
While ML Perf Storage v1.0 does measure traditional storage metrics like throughput, what makes it especially useful for today’s AI landscape, where the major issue is the number of accelerators you can saturate at scale, is that it measures the number of virtual accelerators that are at close to maximum GPU utilization. For each workload, the benchmark output metric is samples per second, subject to a minimum accelerator utilization rate. For the 3D-Unet and Resnet50 benchmarks, each accelerator’s utilization must be 90% or higher to be counted.
It’s notable that no legacy scale-out NAS vendors, including major names like NetApp, Qumulo, and VAST Data, submitted results for the MLPerf Storage Benchmark. Their absence raises questions about why – likely due to the inherent performance bottlenecks in legacy scale-out NAS architectures, which struggle to meet the high-throughput, low-latency demands of AI workloads. Complex file locking, metadata handling, and node-to-node communication often create inefficiencies, limiting their ability to deliver the rapid data access needed to keep GPUs fully utilized.
How to Increase GPU Utilization with a Fit for Purpose System
In contrast, fit for purpose data platforms like WEKA are designed specifically to handle the high IOPS and bandwidth required for AI tasks such as training and inference. By eliminating many of the inefficiencies present in traditional NAS systems, the WEKA® Data Platform consistently delivers superior performance, as demonstrated in the MLPerf benchmarks. This highlights the growing need for purpose-built storage solutions like the WEKA platform, which optimize GPU utilization by delivering low-latency, high-performance data access, ensuring better throughput and faster processing times improves GPU utilization (via fully utilized GPUs), driving improved performance and cost efficiency, particularly in AI and machine learning environments.
The WEKA Data Platform delivered impressive single-client results for 3D-Unet, a deep learning model used for 3D image segmentation tasks such as MRI data processing, and Resnet50, a convolutional neural network model widely applied in image classification, object detection, and facial recognition. Running on a single client, WEKA achieved the #1 spot for A100 tests for both 3D-Unet and Resnet50 and the #2 spot for the H100 tests, but was the top performing globally available product there, too.
For the single client tests in the CLOSED category, WEKA achieved a result of 13 simulated H100 accelerators at over 90% utilization with a peak throughput of 34.57 GB/s for 3D-Unet and 74 simulated H100 accelerators with a peak throughput of 13.72 GB/s for Resnet50. No tuning or changes to the WEKA Data Platform or clients were done between the two runs. These results highlight the WEKA platform’s ability to maximize throughput and accelerate training for AI and ML workloads and efficiently handle memory-intensive and high-volume image classification operations. WEKA additionally ran single client A100 tests, resulting in 24 accelerators at over 90% utilization with 31.12 GB/s for 3D-Unet, and 90 accelerators at 8.68 GB/s for Resnet50. Again, without any tuning changes.
“We can now reach 93% GPU utilization when running our AI model training environment using WEKA on AWS.”
Richard Vencu, MLOps Lead, Stability AI
These results are not surprising to us at WEKA. We regularly see customers with significantly improved GPU utilization when moving their AI and ML data pipelines to the WEKA Data Platform. Stability AI saw their GPU utilization for AI workloads go from 30% to 93% during AI model training after moving their cloud-based GenAI workloads to the WEKA platform.
Using Benchmarks to Compare GPU Utilization
It’s important to have apples-to-apples comparisons in storage benchmarks to ensure that configurations and tests are being compared fairly. By comparing systems with equivalent configurations and under identical test conditions, benchmarks provide an accurate and reliable assessment of how the systems perform in a given scenario, ensuring informed and objective decisions. We applaud MLCommons for taking an approach of having audited benchmarks that create a standard that can help with comparisons. That said, different storage systems can have varying architectures, capacities, and optimizations, so if the configurations, workloads, and testing environments aren’t aligned, the results will be misleading. For example, comparing storage performance using different file sizes, network setups, or cache settings skews the outcome and doesn’t reflect the real differences in the underlying storage solutions.
When reviewing the ML Perf Storage v1.0 benchmarks, it’s crucial to compare similar tests with the same number of clients to ensure accurate and fair assessments. Comparing OPEN results where test code can be modified to CLOSED results where it is fixed is not valid. Comparing single-client results with multi-client results is also not valid. However, comparing just single-client results from the ML Perf Storage v1.0 benchmarks provides a more accurate reflection of performance. For instance, the results for 3D-Unet A100 and H100 and Resnet50 A100 and H100 demonstrate significant differences between vendors, highlighting the importance of having similar test environments for fair comparisons. As an example of this, single-client results for the four commercially available products show the following:
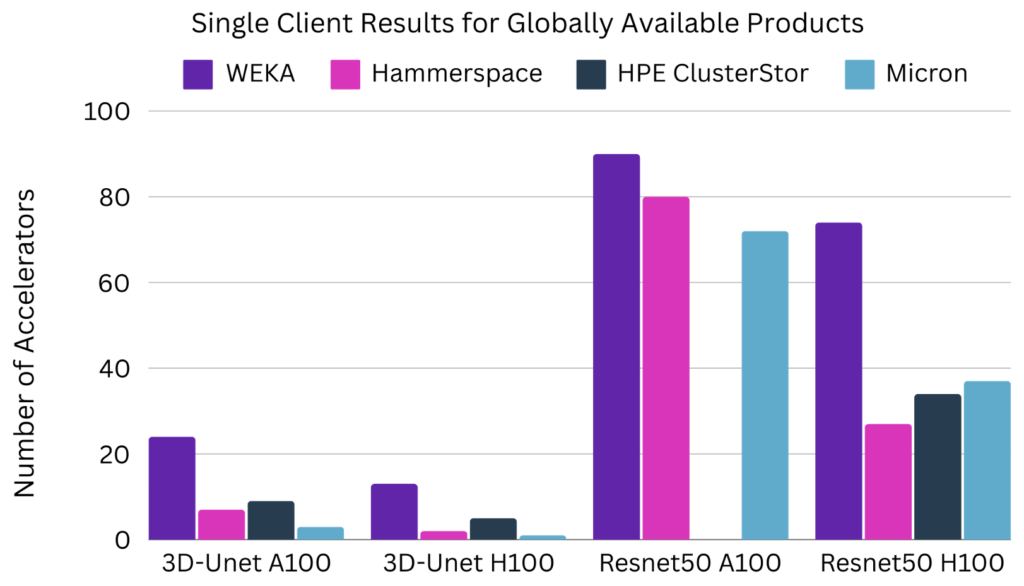
Other vendors had test runs with 5 or more clients that produced a significantly higher number of simulated accelerators compared to their single client results. WEKA’s modeling estimates that with the same 5 clients we would still have anywhere from 2-6x higher numbers of simulated A100 and H100 GPUs than the other vendors’ results.
What these Numbers Mean For You
Being able to saturate more accelerators with a single client means a more efficient and cost effective GPU deployment. You need a smaller storage footprint to maximize GPU utilization. The resource efficiency enabled by WEKA’s high-performance density allows customers to achieve much greater GPU utilization with fewer infrastructure components. By optimizing data flow and minimizing latency, WEKA ensures that GPUs spend less time idle and more time executing intensive tasks such as training and inference. This improved GPU efficiency translates directly to higher throughput and faster completion of workloads, maximizing performance per GPU, reducing bottlenecks, and reducing data center footprint and complexity.
Compared to legacy storage approaches, the WEKA Data Platform can reduce your data center footprint by 20x while simultaneously driving the aforementioned GPU utilization improvements. WEKA can deliver 1TB/s of read bandwidth with less than half a rack – 2-4 times less than competitors – and significantly increasing IOPS and enabling faster data access for GPUs. On the write side, WEKA uses just one rack to achieve the same bandwidth that some competitors require nine for, all while tripling IOPS and maximizing GPU utilization for enhanced AI performance and efficiency.
As AI and machine learning workloads continue to grow in complexity and scale, the limitations of legacy scale-out NAS architectures become increasingly apparent. The absence of these vendors from the MLPerf Storage Benchmark highlights the inability of traditional solutions to meet the high-throughput, low-latency demands of modern AI environments that give rise to GPU utilization challenges. In contrast, fit for purpose data platforms like WEKA, which excelled in the MLPerf benchmarks, demonstrate the importance of purpose-built storage solutions designed to handle massive data loads while maintaining peak GPU utilization. WEKA’s optimized performance, high IOPS, and efficient data handling eliminate bottlenecks that hinder AI infrastructure, empowering organizations to fully leverage their GPU resources. By addressing challenges that traditional storage systems cannot and proving its capabilities through MLPerf benchmarks, WEKA is helping drive AI innovation, delivering superior performance and cost savings for businesses seeking to stay competitive in the rapidly advancing AI landscape.
Popular Blogs From Colin Gallagher



Related Assets
-
The Buyer’s Guide to AI Storage

The Buyer’s Guide to AI Storage
-
See NeuralMesh in Action

See NeuralMesh in Action
-
Practical Strategies for Navigating the Memory Shortage

Practical Strategies for Navigating the Memory Shortage