Fit for Purpose: Part Two – Client Access

While NFS has been the go-to file sharing protocol for decades, its design prioritizes convenience over performance and efficiency, making it insufficient for today’s applications that demand extreme throughput and incredibly low latency. At WEKA we emphasize the importance of being “fit for purpose,” meaning a system is specifically designed to meet the exact needs of a task, ensuring optimal efficiency and effectiveness. Enter the WEKA client—engineered from the ground up to help accelerate data-intensive AI and ML workloads. Curious how the WEKA client outperforms NFS? Keep reading to see how WEKA delivers up to 7.5 times higher throughput and 13 times more IOPS than NFS, all while using fewer CPU resources—making it the choice for modern data-intensive workloads.
NFS – Convenient File Sharing
Many customers use the Network File System, more commonly known as NFS, for their file workloads because it has been a reliable and widely adopted protocol for networked file systems for decades. It allows for easy sharing of files across multiple clients in a network, making it a convenient solution for collaborative environments. NFS is well-integrated with Unix/Linux systems, providing seamless access and compatibility for many applications and workloads.
However, NFS was designed with convenience as the primary objective, not speed. It aimed to simplify the process of file sharing and management across distributed systems, prioritizing ease of use over high performance. As a result, while NFS is highly effective for basic file sharing and straightforward networked environments, it is not fit for the demands of modern data-intensive applications that require high throughput and low latency.
Over the years, NFS has undergone several updates to improve its functionality and performance. Today there are only two versions of the NFS protocol in use; NFSv3, published in 1995, and NFSv4, in 2000. Even now, nearly 30 years after its publication, NFSv3 is still by far the most common version of the protocol and has become the lowest common denominator of storage because almost all operating systems can access NFS version 3 storage. However, NFS’s foundational design remains focused on convenience.
The Limitations of NFS
NFS has several limitations that impact its performance, scalability, and reliability in modern data environments. It often struggles with high I/O workloads and high concurrency, leading to performance bottlenecks. Additionally, NFS was not designed for large-scale, distributed systems, making it difficult to scale efficiently as the number of clients and the size of data grow. Traditional NFS setups can create single points of failure, where the failure of a single server can lead to significant downtime and data availability issues. Latency issues are also common, particularly in geographically distributed environments, affecting the performance of latency-sensitive workloads.
Moreover, NFS has limited protocol support, primarily optimized for Unix/Linux environments, and its security features are relatively basic, often lacking robust measures needed for stringent security requirements. The management of NFS in large, dynamic environments can be complex and labor-intensive, involving handling mount points, export configurations, and network settings. Additionally, NFS’s file locking mechanisms can lead to issues such as file corruption and data inconsistencies in multi-client environments. These limitations make NFS less fit for high-performance, scalable data environments, prompting the need for advanced solutions that offer superior performance, scalability, and more robust features for modern cloud and AI workloads.
The WEKA Client
A decade ago we started with a clean sheet design for a modern, highly optimized approach to data management, built from scratch to leverage the latest hardware technologies and meet the needs of contemporary data-intensive applications. The result was the AI-Native WEKA Data Platform™ that combines performance, scalability, ease of management, and robust security to provide a comprehensive solution for enterprise data environments.
As part of this clean sheet approach we took a fresh approach to client access as well, and developed our WEKA client. The WEKA client is a crucial component of the WEKA Data Platform, designed to deliver exceptional performance and simplify data management for modern, data-intensive applications. It provides high throughput and low latency, making it ideal for AI, ML, and HPC workloads. The WEKA client seamlessly integrates with existing IT infrastructure, supporting various operating systems and hardware configurations, which allows organizations to deploy WEKA without significant changes to their environments. Its scalability ensures it can handle growing data volumes and increased workload demands, supporting both scale-up and scale-out architectures suitable for enterprises of all sizes.
Unlike NFS, the WEKA client was designed to provide high-performance access to data stored on the WEKA Data Platform. The WEKA client leverages advanced algorithms and optimizations tailored to modern hardware and workload demands, ensuring maximum throughput and minimal latency. WEKA also supports data access via NFS to accommodate legacy applications and we have worked to optimize it for maximum throughput, but NFS is primarily used as a compatibility layer rather than an optimal solution. For best results with GPU-Accelerated servers, we recommend mounting with the WEKA client and not NFS.
The WEKA client supports full POSIX semantics, providing a familiar and comprehensive set of file system operations that are crucial for compatibility with a wide range of applications. This ensures that applications requiring POSIX compliance can seamlessly interact with the WEKA Data Platform without the need for modification. Additionally, the WEKA client leverages lockless queues for I/O operations, which significantly reduces overhead and contention typically associated with traditional locking mechanisms. This design choice ensures low-latency and high-throughput access to data, making it ideal for environments where performance is critical.
The WEKA client is adept at handling large-scale data operations, making it a perfect fit for demanding applications such as AI, machine learning, and high-performance computing (HPC). One way the WEKA client achieves this is by providing an advanced caching capability, called adaptive caching, that allows users to fully leverage the performance advantages of Linux data caching (page cache) and metadata caching (dentry cache) while ensuring full coherency across the shared storage cluster. NFSv3 does not support coherency so utilizing Linux caching can lead to data inconsistency for read cache and potential data corruption for write cache.
Additionally, the WEKA client leverages the massive parallelism of our distributed architecture to execute multiple operations concurrently, significantly speeding up data processing and enabling efficient handling of large-scale datasets. And, WEKA’s metadata management system employs sharding to distribute metadata across every storage node, ensuring scalability and fault tolerance. This sharding approach allows for parallel processing and load balancing, which optimizes metadata retrieval times and enhances the system’s ability to handle large-scale data operations without performance degradation. This high-performance access allows AI and ML models to train faster and HPC applications to process data more swiftly, leading to reduced time-to-insight and enabling more rapid innovation.
Comparing WEKA to NFS
To see how much of a better fit the WEKA client is for data-intensive workloads over NFS,we decided to measure and compare the CPU utilization of NFS and WEKA when performing large sequential operations (bandwidth-based tests) and small random operations (IOPS-based tests).
First, a quick primer on the WEKA client. It supports two modes when mounting – Dedicated mode and Shared mode. In Dedicated mode, the WEKA client is allocated dedicated CPU cores from the host upon mount. These cores aren’t shared with other applications running on the host. The WEKA client will run dedicated allocated cores at 100% utilization, allowing the client to constantly check for I/O. Dedicated mode guarantees performance because there’s no CPU contention on cores dedicated to the WEKA client for I/O. Shared mode doesn’t dedicate any cores to the WEKA client and therefore the WEKA client, much like NFS, must contend with other applications for available CPU cycles. In most scenarios, Shared mode can deliver the same degree of performance as Dedicated mode, however Shared mode performance may vary slightly based on CPU contention from other applications running on the host.
The number of CPU cycles consumed by NFS operations can vary significantly depending on several factors, including the type of operations being performed, the network speed, and the server and client hardware configuration. The same logic applies when mounting with the WEKA client in Shared mode, when not dedicating CPU cores.
How and What We Tested
Contrary to popular belief, mounting with the WEKA client is very easy. Because the WEKA client exists in user space, there’s no need to compile your kernel in order to mount with POSIX access. Simply run mount -t wekafs -o net=<netdev> -o cores=4 -o dedicated_mode=none <backendN>/<fs> /mnt/weka to issue a mount. This command will mount the WEKA file system, with up to 4 CPU cores in shared mode using the WEKA client for I/O. No additional tuning or mount options are required to achieve the advertised performance of WEKA.
For NFS, we used nconnect which enables multiple TCP connections for a single NFS mount and can significantly improve NFS performance in a non-proprietary way. We ran mount-t nfs -o nconnect=16 <backendN>:/<fs> /mnt/weka to establish an NFS mount to the WEKA file system.
Benchmarking was performed from a single HDR InfiniBand (IB) connected client server. To avoid resource contention, we only had a single mount active when benchmarking; either via NFS with nconnect or via the WEKA client, but never both simultaneously. We used a common load generating tool, FIO, to issue small and large reads and writes against each mount. We used the following FIO job files to execute load against an NFS mount and a WEKA client mount.
| Throughput-oriented load: | IOPS-oriented load: |
| [global] filesize=2G time_based=1 startdelay=5 exitall_on_error=1 create_serialize=0 filename_format=$filenum/$jobnum directory=/mnt/weka group_reporting=1 clocksource=gettimeofday runtime=30 ioengine=libaio disk_util=0 direct=1 [fio-createfiles-00] stonewall numjobs=64 blocksize=1Mi description=’pre-create files’ create_only=1 [fio-bandwidthSR-00] stonewall numjobs=32 description=’Sequential Read bandwidth workload’ blocksize=1Mi rw=read iodepth=1 | [global] filesize=2G time_based=1 startdelay=5 exitall_on_error=1 create_serialize=0 filename_format=$filenum/$jobnum directory=/mnt/weka group_reporting=1 clocksource=gettimeofday runtime=30 ioengine=libaio disk_util=0 direct=1 numjobs=64 [fio-createfiles-00] stonewall blocksize=1Mi description=’pre-create files’ create_only=1 [fio-iopsR-00] stonewall description=’Read iops workload’ iodepth=8 bs=4k rw=randread |
In addition to running FIO, we capture verbose CPU metrics by running the following command:
while true; do /usr/bin/mpstat | grep all; sleep 1; done
Bandwidth Results
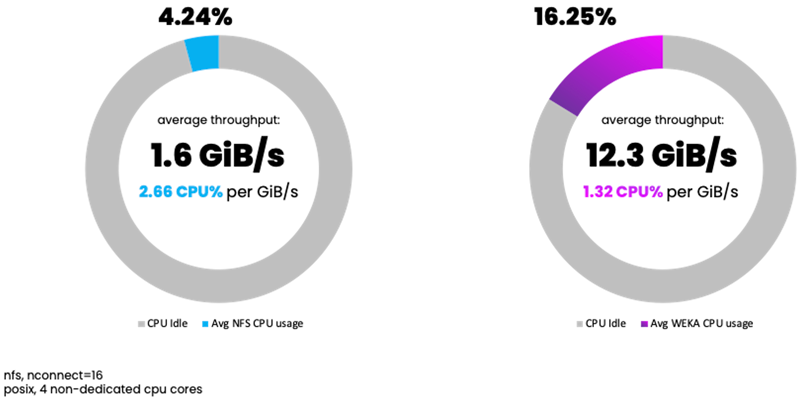
What we observed for bandwidth-oriented benchmarks was that NFS delivered an average of 1.6 GiB/s, consuming 4.24% CPU utilization. WEKA delivered an average of 12.3 GiB/s throughput – 7.5X more, consuming 16.25% CPU utilization. While driving higher CPU utilization over all, the WEKA client uses half the CPU resources per unit of data processed.
NFS w/ nconnect: 2.66% CPU utilization per GiB/s
WEKA Client: 1.32% CPU utilization per GiB/s
IOPS Results
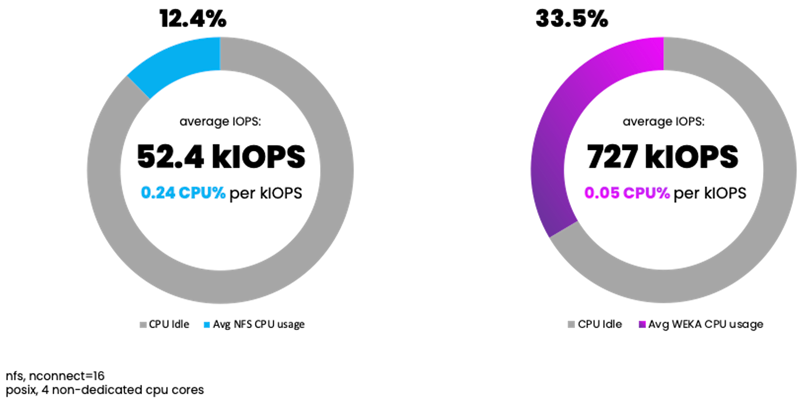
For IOPS-oriented benchmarking, we observed NFS delivering an average of 52.4 kIOPS, consuming 12.4% CPU utilization. WEKA delivered an average of 727 kIOPS, consuming 33.5% CPU utilization.
NFS w/ nconnect: 0.24% CPU utilization per kIOPS
WEKA Client: 0.05% CPU utilization per kIOPS
In a nutshell, the WEKA client absolutely crushed NFS, delivering 7.5X the throughput and a jaw-dropping 13X the IOPS, again with fewer CPU resources used per unit of data processed giving that processing power back to the applications on the client, driving higher utilization.
Conclusion
While NFS has been a reliable and widely adopted protocol for decades, its design prioritizes convenience over performance, making it less suitable for modern, data-intensive applications. Despite updates over the years, NFS still struggles with high I/O workloads, scalability, and latency, especially in demanding environments like AI, ML, and HPC. The WEKA client, on the other hand, was built from the ground up to be fit for the needs of modern applications, offering significantly better performance, scalability, and ease of management.
Our benchmarks clearly demonstrate that the WEKA client outperforms NFS by a wide margin, delivering up to 7.5 times higher throughput and 13 times more IOPS while consuming significantly fewer CPU resources per unit of data processed. This makes the WEKA client the superior choice for organizations seeking to optimize their data infrastructure for high-performance workloads, ensuring faster data access, reduced time-to-insight, and greater overall efficiency in modern enterprise environments.
More Ways WEKA is Fit for Purpose
To learn about other ways WEKA is fit for purpose for AI/ML workloads, see “Fit for Purpose: Part One – Networking” on where we explore the advantages of purpose-built networking systems over legacy solutions, particularly in the context of AI workloads by reducing complexity, minimizing infrastructure costs, and ensuring scalability, which is crucial for efficiently handling large-scale AI operations.
Popular Blogs From Adam Fowler

Related Assets
-
Fit for Purpose: Part One – Networking

Fit for Purpose: Part One – Networking
-
Practical Strategies for Navigating the Memory Shortage

Practical Strategies for Navigating the Memory Shortage
-
The AI Factory Blueprint: Designing for Scalable, Efficient Inference

The AI Factory Blueprint: Designing for Scalable, Efficient Inference