We Don’t Make the GPU, We Make it Faster.

GPUs have become the de-facto standard for data intensive workloads, such as AI model training, computational chemistry and biology, and media and entertainment rendering. But what happens if your GPUs aren’t being utilized to their full extent? Data hungry GPUs sitting idle at the end of a congested data pipeline cost time, money, and lead to a unsustainable footprint. In WEKA’s experience with our GPU-centric customers doing AI model training, we’ve found that it’s not unusual to see GPUs running at less than 25% utilization in many cases. And even for the GPUs that have higher utilization rates, many companies are wondering why they aren’t processing as fast as advertised.
It begs the question: In this era of ultra-high performance compute and networking, how do we make the GPUs perform as expected?
There are several key reasons to dig into as to why this problem occurs, and we should start by breaking the problem up into two discrete areas:
- Data movement while filling a data pipeline to get data to the GPU
- IO patterns while the GPU is accessing data
The first problem originates from a situation that we’ve described before: Copying data between infrastructure to optimize each part of a data pipeline. This is a legacy approach that creates data stalls during every copy operation. While it’s tempting to think of this only happening when copying between silos of infrastructure, the reality is that many customers have consolidated their data onto a single storage system, and still need to copy it within the storage into separate portions that are optimized for a particular type of IO. The infrastructure may have moved into a single system, but the problem still remains. As an example, Synthesia, who builds lifelike video content via generative AI ran into this specific problem. Synthesia was manually loading their model training data onto local drives in every GPU server in their cloud-based training cluster due to the performance limitations of Lustre-based storage in AWS. This stall while their scientists waited around to run the models resulted in significant delays before running of the model.
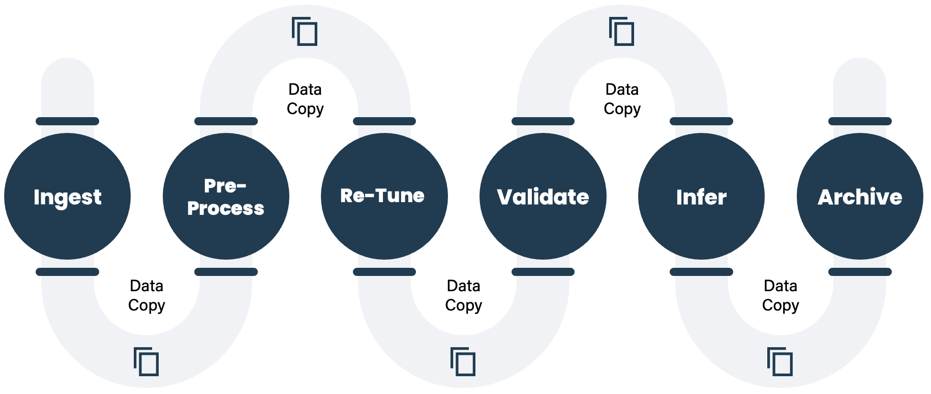
Data copies between stages of an AI data pipeline
The second problem is how the IO patterns bottleneck the entire data pipeline. There is some nuance about how the IO patterns create a bottleneck. To start with, WEKA has found that when data sources are brought into a training pipeline, the data often is in the form of LOTS of small files. This is a scaling problem that many storage systems struggle to handle.
For example, one WEKA customer working on autonomous driving technology uses an average of 14 million image files that are updated on a regular basis as the input for each model training run. Another customer, a large investment bank, is using queries against 8 billion files of historical data to train the model on financial analysis. Where this becomes tricky is that it’s not just the IO going directly into the GPU. The various stages of the data pipeline all have IO needs that can bottleneck. The 14 million files? They need to be tagged, indexed, normalized for color, size, etc. which generates significant read AND write IO at the beginning of the pipeline. And then later, once the data is set to go into the GPU, the training cycle then has to do lookups of all the files as it pulls them in creating a massive amount of metadata operations. In the two use cases listed here, metadata overhead can be as high as 75% for various stages of the pipeline.
This combination of reads and writes early in the pipeline, and then lots of random reads from the model training with the need for low-latency writes for checkpointing along with metadata overhead creates a vicious cycle that puts immense pressure on the storage system to try and keep up with each stage of the data pipeline.
The WEKA Data Platform™ not only can keep up, but it helps unleash your GPUs to do the most efficient work possible. WEKAs’ zero-copy and zero-tuning architecture means that the compromises of the past have gone away. WEKA enables data to be shared across all systems in a data pipeline, preventing the need to copy data across each stage of the pipeline. And because WEKA is so performant across any type of IO including metadata heavy operations, we then see acceleration of data movement into CPUs and GPUs for processing.
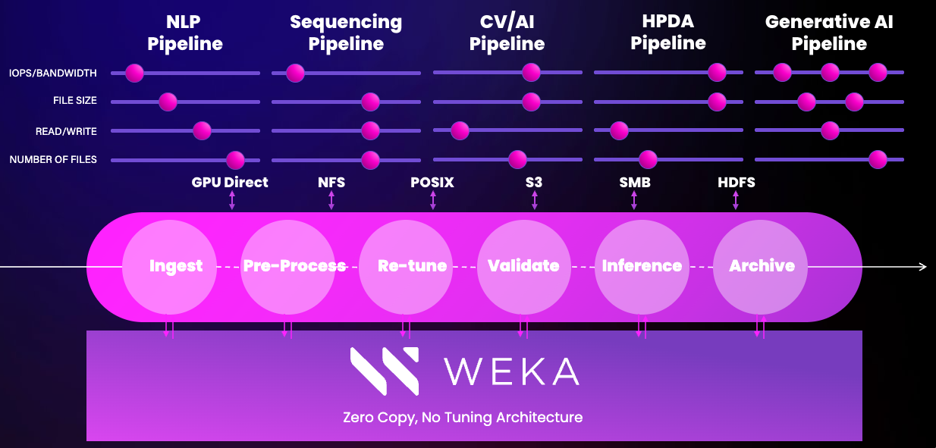
The WEKA Data Platform handling any IO pattern
Customers have seen huge improvements when deploying the WEKA Data Platform. Synthesia saw significant GPU utilization improvements by removing hours of data copying from their pipeline. The autonomous driving developer? Compared to the dedicated all-flash storage system they were using, they watched each training epoch drop from ~2 weeks down to 4 hours, a 20x improvement. Another customer, Atomwise, saw data movement for pre-processing across various stages in their pipeline improve by 40x, and model training performance improve by 2x, an overall pipeline time improvement of nearly 20x as well.
When WEKA is put into a modern data pipeline, it increases GPU utilization, provides performance density that enables sustainable AI, and allows our customers to get quicker answers, solve more problems, and focus on enhancing their business. With a hat tip to BASF, I’m going to co-opt their tagline here: WEKA doesn’t make the GPU, we make it faster.
Popular Blogs From Joel Kaufman



Related Assets
-
2024 AI Trends: Scaling Innovation, Generative AI, and Infrastructure Challenges

2024 AI Trends: Scaling Innovation, Generative AI, and Infrastructure Challenges
-
Turbocharge AI Workloads with an AI-Native Data Platform

Turbocharge AI Workloads with an AI-Native Data Platform
-
Supercharging GPU Cloud for AI Workloads

Supercharging GPU Cloud for AI Workloads