The Challenge of IO for Generative AI: Part 2

Consolidation, Pipelines, and the IO Blender
As we saw in Part 1, the trend in Generative AI (GenAI) and AI infrastructure is to move away from siloed and tiered deployments where the data for each processing step is independently managed, and head toward a consolidated environment where a single storage platform handles the entire data pipeline for ease of management, prevention of “silo sprawl”, and to help alleviate resource availability pressures. In the previous blog, we showed the data movement flow as it relates to infrastructure. Now, let’s take a slightly different view of how GenAI data works inside a consolidated environment.
Simplified GenAI Data Pipeline
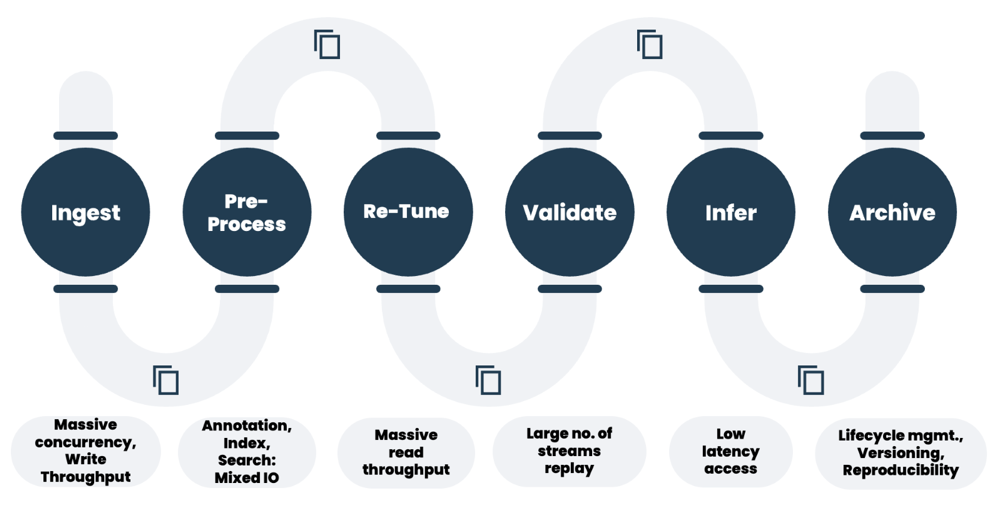
Even though the infrastructure has changed, the IO requirements for all the different steps in an AI data pipeline have not. Each one of these AI pipeline steps usually has a completely different profile for what the data looks like. And, when you have different IO demands to work on the data throughout the pipeline, this can cause issues with traditional storage. Some steps need low latency and random small IO. Others need massive streaming throughput. Still others need a concurrent mix of the two because of sub-steps within the process. As we explore this topic, it’s key to understand that when we talk about a pipeline, we’re talking about a singular pipeline process. In many cases, there can be multiple overlapping pipelines running against the same system at any given time.
The single pipeline makes it difficult to optimize a storage system for any particular stage of the pipeline, but overlapping pipelines in a consolidated environment brings out the dreaded IO blender problem. While originally coined for Virtual Machine consolidation, this same concept also applies to GenAI Data Pipelines.
Multi-pipeline impact on IO profiles
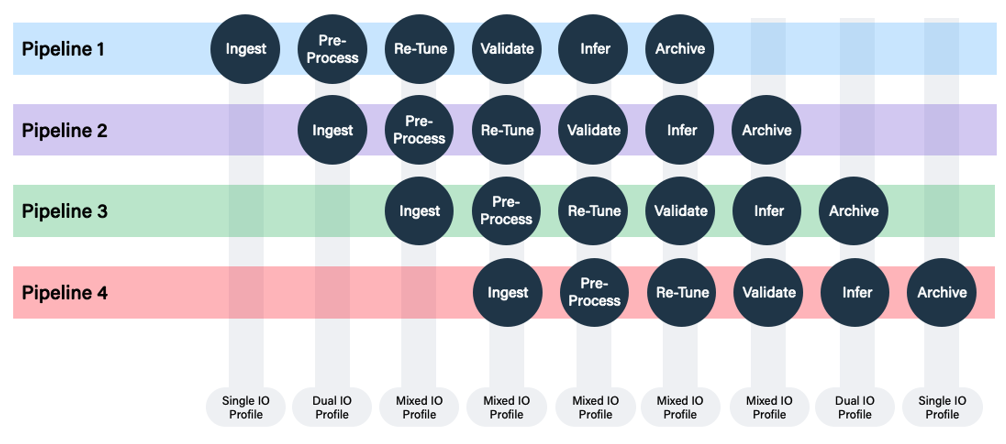
When the GenAI pipelines are overlapped, a storage system no longer has to deal with just discrete IO for every step in a pipeline, but now has to handle the mixed IO from different stages of every pipeline simultaneously. Think of various researchers or developers kicking off training and/or re-tuning jobs at different times. The overlap blurs the IO patterns to the point where the storage system is dealing with a mixed IO profile that tends to be random in nature. This mixed IO has become quite typical in GenAI environments, and stresses most traditional storage and filesystems that were originally developed to handle one or two types of siloed IO. Ultimately, mixed IO can slow down environments enough that customers feel the tradeoff for consolidation may not have been worth it.
A number of the performance issues with mixed IO in GenAI environments can be related to a hidden problem that comes with it: metadata overhead.
Stay tuned for part 3, where we’ll discuss metadata and some individual GenAI IO stages that influence a storage system’s ability to provide the highest levels of performance for AI workflows.
Popular Blogs From Joel Kaufman



Related Assets
-
Gorilla Guide to High Performance Data in the Cloud

Gorilla Guide to High Performance Data in the Cloud
-
Unlocking AI Potential: Modern Data Strategies for Growth

Unlocking AI Potential: Modern Data Strategies for Growth
-
Turbocharge AI Workloads with an AI-Native Data Platform

Turbocharge AI Workloads with an AI-Native Data Platform